啊今天又开始进行机器学习的学习,东西越来越多了!
什么是机器学习?
机器学习的核心是“使用算法解析数据,从中学习,然后对世界上的某件事情做出决定或预测”。这意味着,与其显式地编写程序来执行某些任务,不如教计算机如何开发一个算法来完成任务。
即 数据、模型 和 预测。
从历史数据中获得规律,那么这些数据是什么格式的呢?
数据集构成:特征值 + 目标值
算法分类
有三种主要类型的机器学习:监督学习、非监督学习和强化学习,所有这些都有其特定的优点和缺点。
1、监督学习
监督学习涉及一组标记数据。计算机可以使用特定的模式来识别每种标记类型的新样本。监督学习的两种主要类型是分类和回归。
即 : 目标值是类别的,属于分类问题;目标值是连续型的数据的,属于回归问题。
分类
在分类中,机器被训练成将一个组划分为特定的类。分类的一个简单例子是电子邮件帐户上的垃圾邮件过滤器。过滤器分析你以前标记为垃圾邮件的电子邮件,并将它们与新邮件进行比较。如果它们匹配一定的百分比,这些新邮件将被标记为垃圾邮件并发送到适当的文件夹。那些比较不相似的电子邮件被归类为正常邮件并发送到你的邮箱。
算法举例:K-临近算法、贝叶斯分类、决策树与随机森林、逻辑回归
回归
在回归中,机器使用先前的(标记的)数据来预测未来。天气应用是回归的好例子。使用气象事件的历史数据(即平均气温、湿度和降水量),你的手机天气应用程序可以查看当前天气,并在未来的时间内对天气进行预测。
算法举例:线性回归、岭回归
2、非监督学习
在无监督学习中,数据是无标签的。由于大多数真实世界的数据都没有标签,这些算法特别有用。无监督学习分为聚类和降维。聚类用于根据属性和行为对象进行分组。这与分类不同,因为这些组不是你提供的。聚类的一个例子是将一个组划分成不同的子组(例如,基于年龄和婚姻状况),然后应用到有针对性的营销方案中。降维通过找到共同点来减少数据集的变量。大多数大数据可视化使用降维来识别趋势和规则。
算法举例:聚类、k-means
3、强化学习
强化学习使用机器的个人历史和经验来做出决定。强化学习的经典应用是玩游戏。与监督和非监督学习不同,强化学习不涉及提供“正确的”答案或输出。相反,它只关注性能。这反映了人类是如何根据积极和消极的结果学习的。很快就学会了不要重复这一动作。同样的道理,一台下棋的电脑可以学会不把它的国王移到对手的棋子可以进入的空间。然后,国际象棋的这一基本教训就可以被扩展和推断出来,直到机器能够打(并最终击败)人类顶级玩家为止。
开发流程
主要分为六个阶段:
- 获取数据
- 数据处理
- 特征工程
- 机器学习算法训练 - 模型
- 模型评估(是否符合要求,不符合则转到 2 步骤继续循环,直到符合要求)
- 应用
常用算法简介
回归算法
这可能是最流行的机器学习算法,线性回归算法是基于连续变量预测特定结果的监督学习算法。另一方面,Logistic回归专门用来预测离散值。这两种(以及所有其他回归算法)都以它们的速度而闻名,它们一直是最快速的机器学习算法之一。
基于实例的算法
基于实例的分析使用提供数据的特定实例来预测结果。最著名的基于实例的算法是k-最近邻算法,也称为KNN。KNN用于分类,比较数据点的距离,并将每个点分配给它最接近的组。
决策树算法
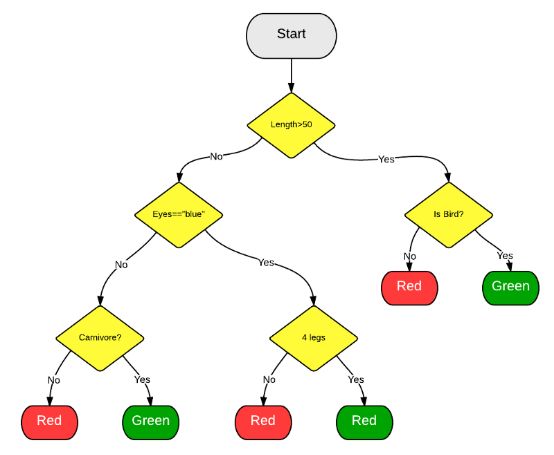
决策树算法将一组“弱”学习器集合在一起,形成一种强算法,这些学习器组织在树状结构中,相互分支。一种流行的决策树算法是随机森林算法。在该算法中,弱学习器是随机选择的,这往往可以获得一个强预测器。在下面的例子中,我们可以发现许多共同的特征(就像眼睛是蓝的或者不是蓝色的),它们都不足以单独识别动物。然而,当我们把所有这些观察结合在一起时,我们就能形成一个更完整的画面,并做出更准确的预测。
贝叶斯算法
丝毫不奇怪,这些算法都是基于Bayes理论的,最流行的算法是朴素Bayes,它经常用于文本分析。例如,大多数垃圾邮件过滤器使用贝叶斯算法,它们使用用户输入的类标记数据来比较新数据并对其进行适当分类。
聚类算法
聚类算法的重点是发现元素之间的共性并对它们进行相应的分组,常用的聚类算法是k-means聚类算法。在k-means中,分析人员选择簇数(以变量k表示),并根据物理距离将元素分组为适当的聚类。
机器学习建议
首先需要明确两点问题:
- 算法是核心,数据与科学是基础
- 找准定位
- 书籍推荐
- 机器学习(西瓜书)– 周志华
- 统计学习方法 – 李航
- 深度学习(花书)
数学基础建议
注意所有对数学恐惧的读者:我很遗憾地告诉你,要完全理解大多数机器学习算法,就需要对一些关键的数学概念有一个基本的理解。但不要害怕!所需的概念很简单,并且借鉴了你可能已经上过的课程。机器学习使用线性代数、微积分、概率和统计。
Top 3线性代数概念:
1.矩阵运算;
2.特征值/特征向量;
3.向量空间和范数
Top 3微积分概念:
1.偏导数;
2.向量-值函数;
3.方向梯度
Top 3统计概念:
1.Bayes定理;
2.组合学;
3.抽样方法
