本篇是python框架Scrapy的初步使用。
创建Scrapy爬虫工程
演示HTML页面地址:http://python123.io/ws/demo.html
文件名称:demo.html
创建步骤
应用Scrapy爬虫框架主要是编写配置型代码.
第一步
建立一个Scrapy爬虫工程。选取一个目录,cmd打开命令行运行下述代码:
1 | scrapy startproject python123demo # python123demo为工程名 |
生成的工程目录

- item.py:用来存储爬虫爬取下来的数据模型。
- middlewares.py:用来存放各种中间件的文件。
- pipelines.py:用来将items模型存储到本地磁盘中。
- settings.py:本爬虫的一些配置信息(比如请求头、多久发送一次请求、ip代理池等)
- scrapy.cfg:项目的 配置文件。
- spider文件夹:所有的爬虫代码文件。
其中spiders/ 目录下的内容为:(后续生成的demo.py便在此文件下)

第二步
在工程中产生一个Scrapy爬虫。进入工程目录(\python123demo目录下),然后执行如下命令:
1 | scrapy genspider demo python123.io |

该命令作用:
(1) 生成一个名称为demo的spider(不能与项目名一致)
(2) 爬取网站的url为 python123.io
(3) 在spiders目录下增加代码文件demo.py
该命令仅用于生成demo.py,该文件也可以手工生成.
demo.py文件

类名为DemoSpider(demo为自己命名的demo文件),且继承自
scrapy.Spidername = “Demo”,当前爬虫名为Demo
allowed_domains: 是最开始在命令行中写入的域名,表示只能爬取该域名以下的相关链接
start_urls: 爬虫启动时最开始的url链接。是包含一个或多个url 的列表
parse:一个解析页面的空方法
第三步
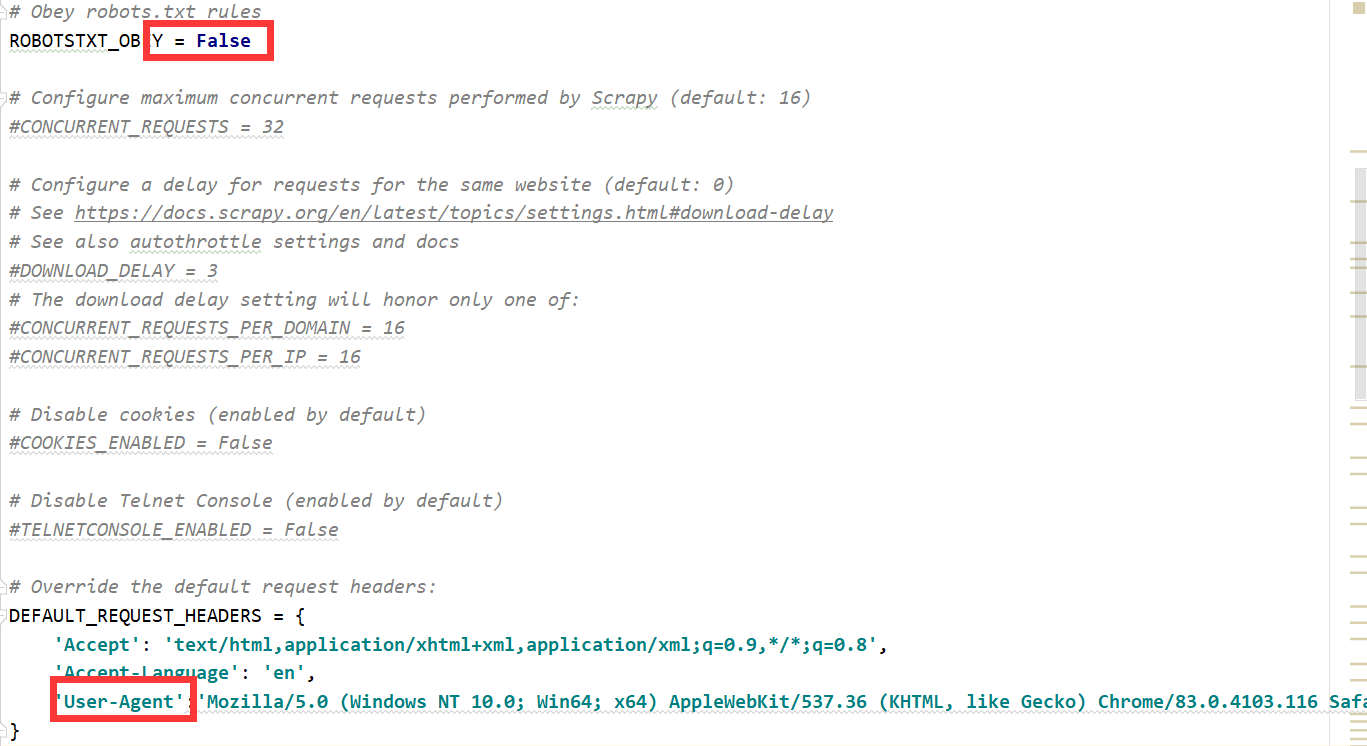
设置settings.py,设置了两个地方,第一是不遵守robots.txt协议(设为False);第二是设置请求头,添加了user-agent选项。
第四步
配置产生的spider爬虫。主要是对demo.py文件的编写修改。(这里的案例以爬取相关网址,获得html,并存储在文件中作为演示)
配置:(1)初始URL地址 (2)获取页面后的解析方式

第五步
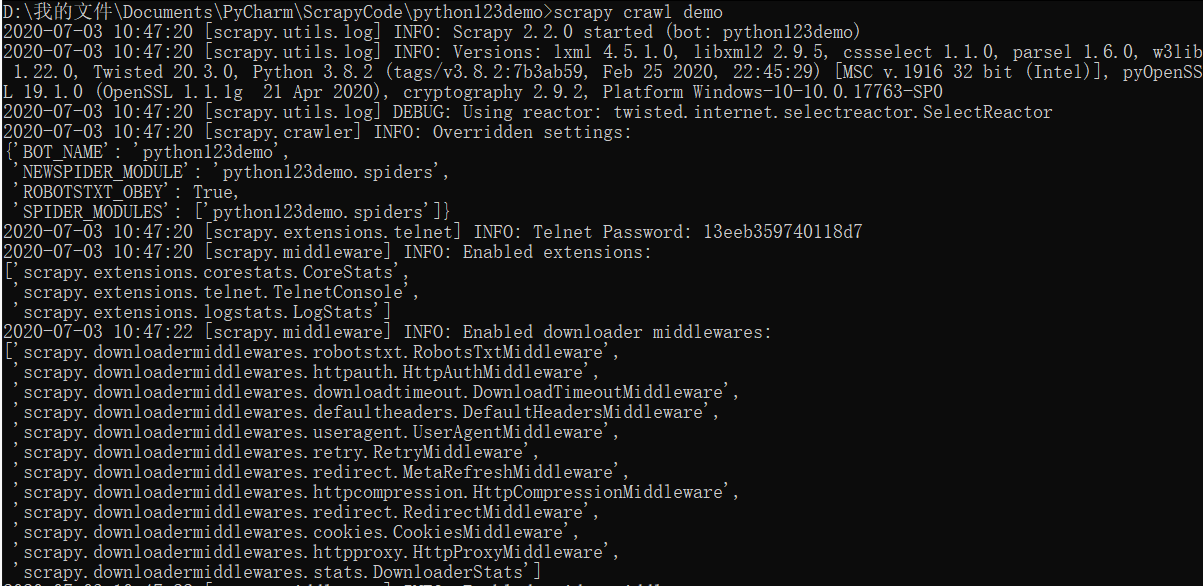
运行爬虫,获取网页
在命令行下,执行如下命令:
1 | scrapy crawl demo |
parse方法中:
fname = response.url.split('/')[-1],意为:从response响应中提取url,把最后的名字(即 ‘/’ 后的名字)作为待存储的本地文件名。
demo爬虫被执行,捕获页面存储在demo.html
demo.py代码的完整版本

demo.py两个等价版本的区别

yield关键字的使用

生成器每调用一次在yield位置产生一个值,直到函数执行结束.
为何要有生成器?


demo.py

Scrapy爬虫的基本使用
Scrapy爬虫的使用步骤
步骤1:创建一个工程和Spider模板
步骤2:编写Spider
步骤3:编写Item Pipeline:对Spider提取信息的后续处理做相关的定义
步骤4:优化配置策略
Scrapy爬虫的数据类型
注意:这里的request类和response类是Scrapy库的,和requests库的不是完全一致,但几乎相同。
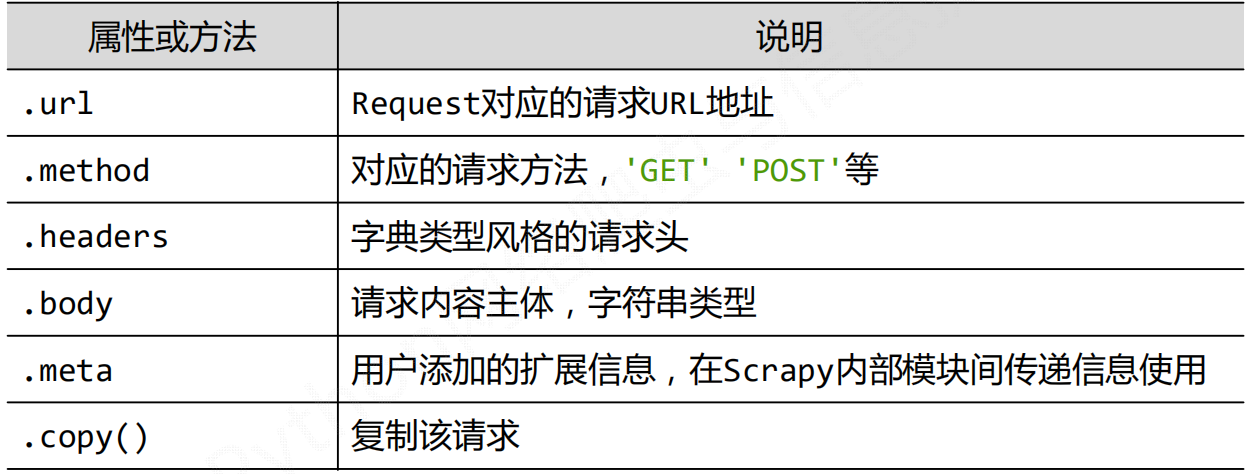
Request类
class scrapy.http.Request()
Request对象表示一个HTTP请求,由Spider生成,由Downloader执行。
属性和方法
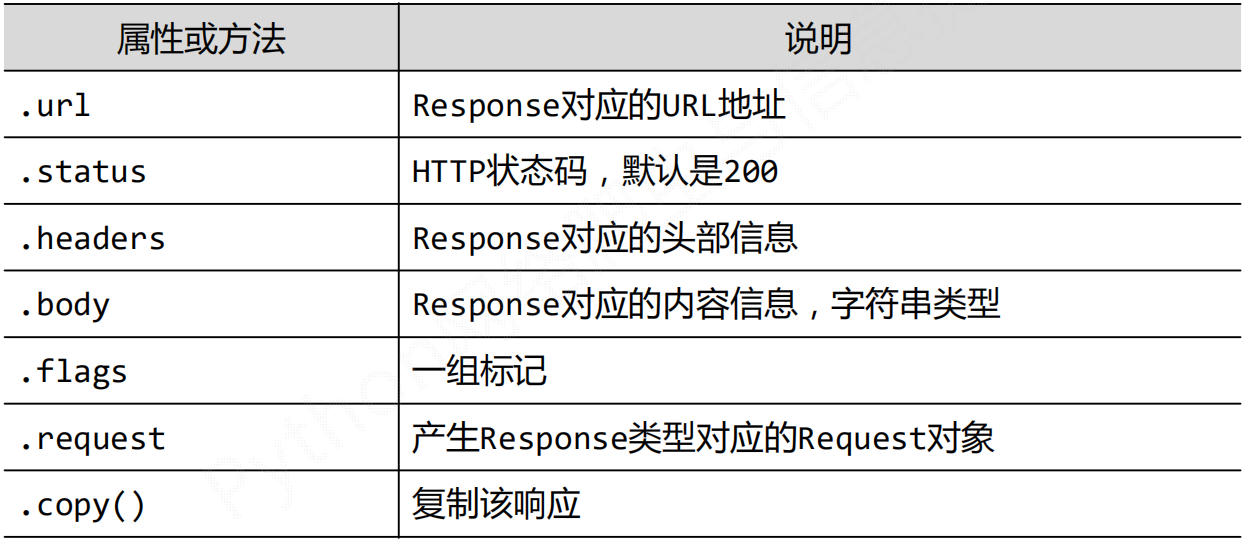
Response类
class scrapy.http.Response()
Response对象表示一个HTTP响应,由Downloader生成,由Spider处理。
属性和方法
Item类
class scrapy.item.Item()
Item对象表示一个从HTML页面中提取的信息内容
由Spider生成,由Item Pipeline处理
Item类似字典类型,可以按照字典类型操作
在scrapy爬虫中,Spider爬取网页,得到的信息以键值对的形式封装成字典,这种字典就是
Item类
Scrapy爬虫提取信息的方法

重点介绍CSS Selector的基本使用。

该方法在scrapy框架中十分常见,比较简单,需要掌握。
补充:Xpath
Xpath在Scrapy框架中常用。
Xpath语法
其实只分为3类
- 层级:
/直接子级,//跳级 - 属性:
@属性访问 - 函数:
contains()、text()等。- contains():检测某个属性并不是完全等于某个值,而是包含某个值。
- text():对标签内的文字结点进行提取。
在Scrapy中的应用
scrapy中支持Xpath的使用,response.xpath()直接调用即可。
案例:糗事百科,提取作者、文章详情页的url,和文章内容
1 | import scrapy |
