本节总结分类算法中的 决策树 和 随机森林 算法。
决策树
决策树思想的来源非常朴素,程序设计中的条件分支结构就是if-then结构,最早的决策树就是利用这类结构分割数据的一种分类学习方法
决策树:是一种树形结构,其中每个内部节点表示一个属性上的判断,每个分支代表一个判断结果的输出,最后每个叶节点代表一种分类结果,本质是一颗由多个判断节点组成的树。
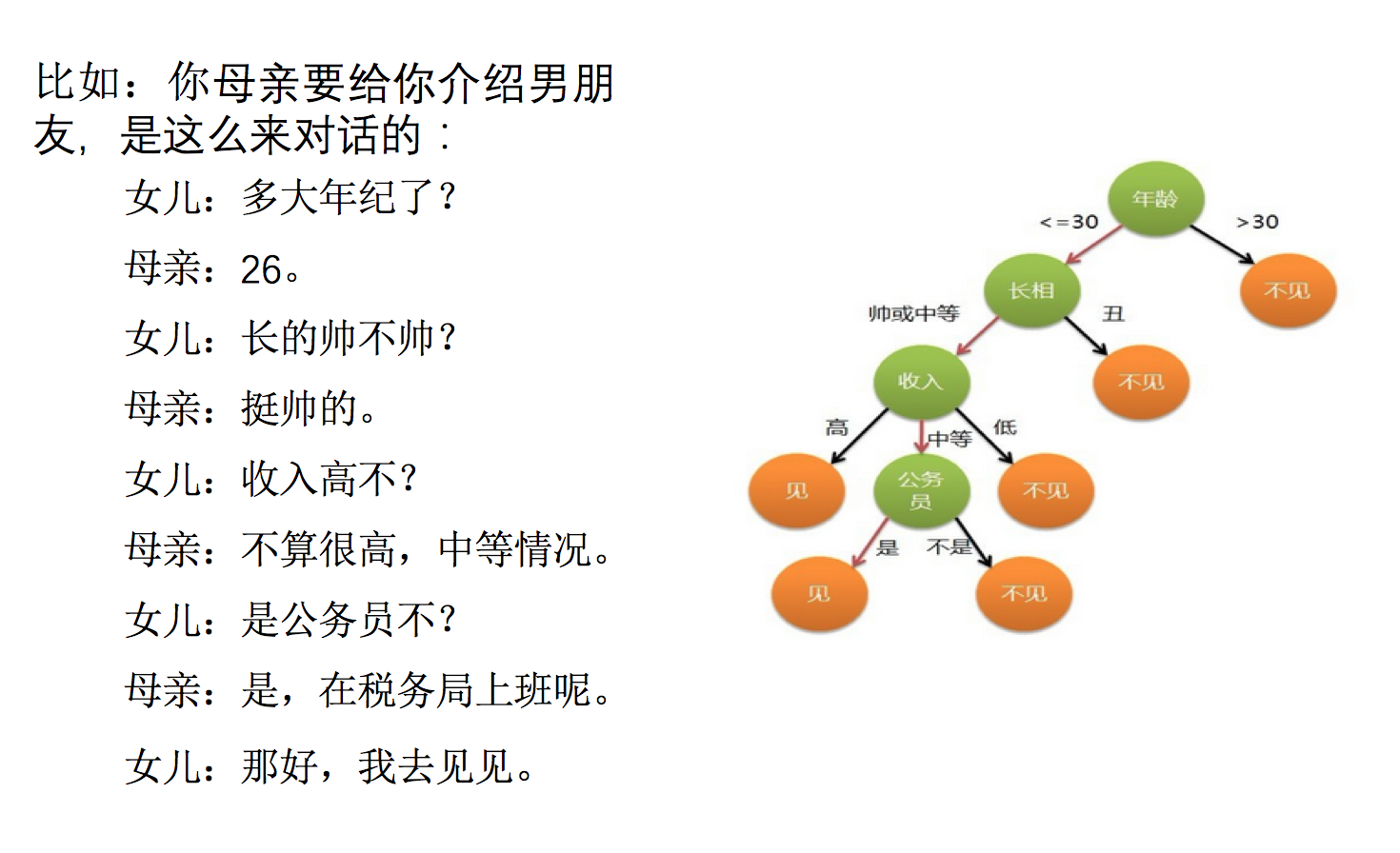
决策树涉及概念较多,不好理解,这里就先给出 API ,学会基本的调用即可。
API
class sklearn.tree.DecisionTreeClassifier(criterion=’gini’, max_depth=None,random_state=None)
- criterion
- 特征选择标准
- “gini”或者”entropy”,前者代表基尼系数,后者代表信息增益。一默认”gini”,即CART算法。
- min_samples_split
- 内部节点再划分所需最小样本数
- 这个值限制了子树继续划分的条件,如果某节点的样本数少于min_samples_split,则不会继续再尝试选择最优特征来进行划分。 默认是2.如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。我之前的一个项目例子,有大概10万样本,建立决策树时,我选择了min_samples_split=10。可以作为参考。
- min_samples_leaf
- 叶子节点最少样本数
- 这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。 默认是1,可以输入最少的样本数的整数,或者最少样本数占样本总数的百分比。如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。之前的10万样本项目使用min_samples_leaf的值为5,仅供参考。
- max_depth
- 决策树最大深度
- 决策树的最大深度,默认可以不输入,如果不输入的话,决策树在建立子树的时候不会限制子树的深度。一般来说,数据少或者特征少的时候可以不管这个值。如果模型样本量多,特征也多的情况下,推荐限制这个最大深度,具体的取值取决于数据的分布。常用的可以取值10-100之间
- random_state
- 随机数种子
可视化
我们可以将训练好后的模型保存到本地,进行直观的可视化。
使用的API如下:
sklearn.tree.export_graphviz() 该函数能够导出DOT格式
- tree.export_graphviz(estimator,out_file=’tree.dot’,feature_names=[‘’,’’])
但保存的 dot 文件是一堆数据,我们可以将数据放到网站上直观显示。
将dot文件内容复制到该网站当中显示
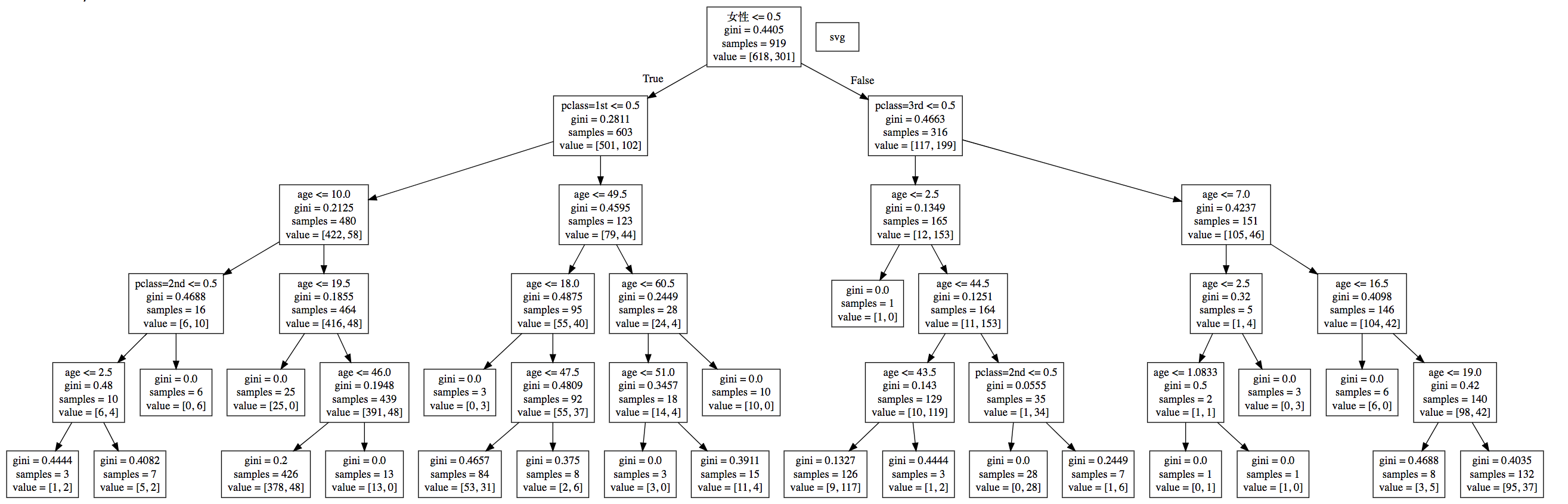
决策树API使用
初步使用
这里先给出一个小的鸢尾花实例,了解决策树的基本使用。
1 | from sklearn.datasets import load_iris |
案例:泰坦尼克号生存预测

经过观察数据得到:
- 1 乘坐班是指乘客班(1,2,3),是社会经济阶层的代表。
- 2 其中age数据存在缺失。
1 | import pandas as pd |
决策树总结
- 优点:
- 简单的理解和解释,树木可视化。
- 缺点:
- 决策树学习者可以创建不能很好地推广数据的过于复杂的树,这被称为过拟合。
- 改进:
- 减枝cart算法(决策树API当中已经实现,随机森林参数调优有相关介绍)
- 随机森林
注:企业重要决策,由于决策树很好的分析能力,在决策过程应用较多, 可以选择特征
集成学习方法之随机森林
什么是集成学习方法
集成学习通过建立几个模型组合的来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成组合预测,因此优于任何一个单分类的做出预测。
什么是随机森林
在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。
例如, 如果你训练了5个树, 其中有4个树的结果是True, 1个数的结果是False, 那么最终投票结果就是True
随机森林原理过程
学习算法根据下列算法而建造每棵树:
- 用N来表示训练用例(样本)的个数,M表示特征数目。
- 1、一次随机选出一个样本,重复N次, (有可能出现重复的样本)
- 2、随机去选出m个特征, m <<M,建立决策树
- 采取bootstrap抽样 (随机有放回抽样)
为什么采用BootStrap抽样
- 为什么要随机抽样训练集?
- 如果不进行随机抽样,每棵树的训练集都一样,那么最终训练出的树分类结果也是完全一样的
- 为什么要有放回地抽样?
- 如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是“有偏的”,都是绝对“片面的”(当然这样说可能不对),也就是说每棵树训练出来都是有很大的差异的;而随机森林最后分类取决于多棵树(弱分类器)的投票表决。
API
class sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion=’gini’, max_depth=None, bootstrap=True, random_state=None, min_samples_split=2)
- 随机森林分类器
- n_estimators:integer,optional(default = 10)森林里的树木数量120,200,300,500,800,1200
- criteria:string,可选(default =“gini”)分割特征的测量方法
- max_depth:integer或None,可选(默认=无)树的最大深度 5,8,15,25,30
- max_features=”auto”,每个决策树的最大特征数量
- If “auto”, then
max_features=sqrt(n_features). - If “sqrt”, then
max_features=sqrt(n_features)(same as “auto”). - If “log2”, then
max_features=log2(n_features). - If None, then
max_features=n_features.
- If “auto”, then
- bootstrap:boolean,optional(default = True)是否在构建树时使用放回抽样
- min_samples_split:节点划分最少样本数
- min_samples_leaf:叶子节点的最小样本数
超参数:n_estimator, max_depth, min_samples_split,min_samples_leaf
案例
利用上面用决策树做过的泰坦尼克号案例来实现随机森林的算法。
1 | import pandas as pd |
随机森林总结
- 在当前所有算法中,具有极好的准确率
- 能够有效地运行在大数据集上,处理具有高维特征的输入样本,而且不需要降维
- 能够评估各个特征在分类问题上的重要性
