本篇开始学习大数据Hadoop技术中的核心之一 —— HDFS。
HDFS概述
介绍
HDFS (Hadoop Distributed File System)是Hadoop抽象文件系统的一种实现。Hadoop抽象文件系统可以与本地系统、Amazon S3等集成,甚至可以通过Web协议(webhsfs)来操作。HDFS的文件分布在集群机器上,同时提供副本进行容错及可靠性保证。例如客户端写入读取文件的直接操作都是分布在集群各个机器上的,没有单点性能压力。
HDFS设计原则
设计目标
- 存储非常大的文件:这里非常大指的是几百M、G、或者TB级别。实际应用中已有很多集群存储的数据达到PB级别。根据Hadoop官网,Yahoo!的Hadoop集群约有10万颗CPU,运行在4万个机器节点上。更多世界上的Hadoop集群使用情况,参考Hadoop官网.
- 采用流式的数据访问方式: HDFS基于这样的一个假设:最有效的数据处理模式是一次写入、多次读取数据集经常从数据源生成或者拷贝一次,然后在其上做很多分析工作
分析工作经常读取其中的大部分数据,即使不是全部。 因此读取整个数据集所需时间比读取第一条记录的延时更重要。 - 运行于商业硬件上: Hadoop不需要特别贵的、reliable的(可靠的)机器,可运行于普通商用机器(可以从多家供应商采购) ,商用机器不代表低端机器。在集群中(尤其是大的集群),节点失败率是比较高的HDFS的目标是确保集群在节点失败的时候不会让用户感觉到明显的中断。
HDFS不适合的应用类型
有些场景不适合使用HDFS来存储数据。下面列举几个:
1) 低延时的数据访问
对延时要求在毫秒级别的应用,不适合采用HDFS。HDFS是为高吞吐数据传输设计的,因此可能牺牲延时HBase更适合低延时的数据访问。
2)大量小文件
文件的元数据(如目录结构,文件block的节点列表,block-node mapping)保存在NameNode的内存中, 整个文件系统的文件数量会受限于NameNode的内存大小。
经验而言,一个文件/目录/文件块一般占有150字节的元数据内存空间。如果有100万个文件,每个文件占用1个文件块,则需要大约300M的内存。因此十亿级别的文件数量在现有商用机器上难以支持。
3)多方读写,需要任意的文件修改
HDFS采用追加(append-only)的方式写入数据。不支持文件任意offset的修改。不支持多个写入器(writer)。
HDFS的架构
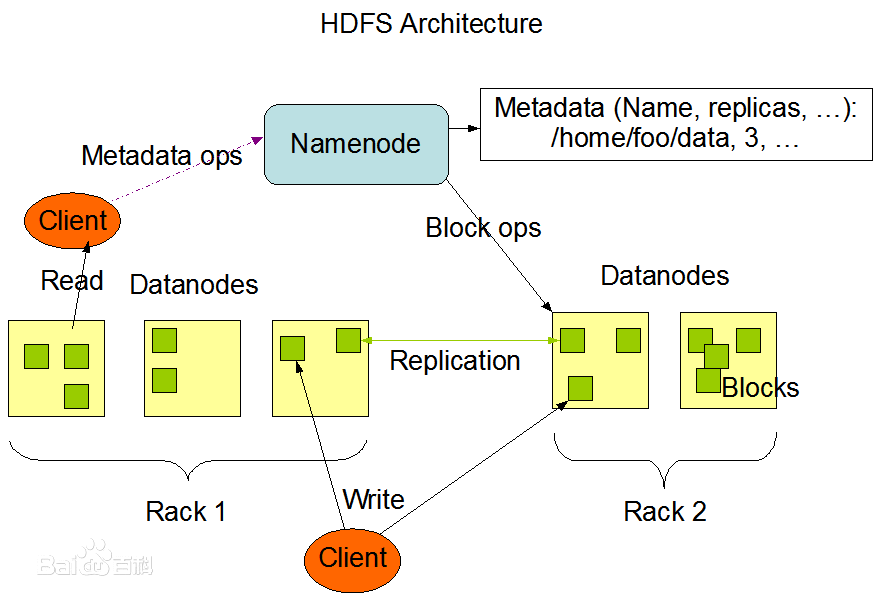
HDFS是一个 主 / 从(Master / Slave)体系结构。
HDFS由四部分组成,HDFS Client、NameNode,DataNode 和 Secondary NameNode。
1、Client:就是客户端
- 文件切片。文件上传到HDFS时,Client将文件切分成一个一个的 Block进行存储。
- 与NameNode交互,获取文件的位置信息。
- 与DataNode交互,读取或者写入数据。
- Client提供一些命令来管理和访问HDFS,比如启动或关闭HDFS。
2、NameNode:就是Master,是一个主管、管理者
- 管理HDFS的名称空间 和 文件数据块(Block)的映射信息,整个HDFS可存储的文件数受限于NameNode的内存大小。在内存中加载文件系统中每个文件和每个数据块的引用关系(文件、Block 和 DataNode之间的映射关系),数据会定期保存在本地磁盘(fsImage 镜像 文件 和 edits 日志 文件)。
- 配置副本策略:文件数据块到底存放到那些DataNode上,是由NameNode决定的,它根据全局情况做出放置副本的决定。
- 处理客户端读写请求。数据流不经过NameNode,会询问它与那个DataNode联系
- NameNode心跳机制:DataNode定期发给NameNode一个个包,称为心跳机制。若NameNode没有收到,则认为相应的DataNode已经宕机,这时候NN准备要把DN上的数据块进行重新复制
3、DataNode :就是Slave。
Name Node下达命令,DataNode执行
- 存储实际的数据块
- 执行数据的 读/写 操作
- 周期性的向NameNode汇报心跳信息、数据块信息 和 缓存数据块信息
4、Secondary NameNode
并非NameNode的热备。当NameNode挂掉时,它并不能马上替换NameNode并提供服务。
- 辅助NameNode,分担其工作量。
- 定期合并fsimage 和 fsedits,并推送给NameNode。
HDFS的副本机制和机架感知
HDFS文件副本机制
所有文件都是以 Block 块的方式存放在HDFS文件系统中,作用如下:
- 一个文件可能大于集群中任意一个磁盘,引入块机制分布存储可以解决该问题。
- 使用块作为文件存储的逻辑单位可以简化存储子系统
- 块非常适用于数据备份进而提供数据容错能力
Block的块大小可以通过hdfs-site.xml当中的配置文件进行指定,默认128M。
1 | <property> |
机架感知
HDFS分布式文件系统的内部有一个副本存放策略:以默认的副本数 = 3 为例:
1、第一个副本块存本机
2、第二个副本块跟本机同机架内的其他服务器结点
3、第三个副本块存不同机架的一个服务器结点上
HDFS的命令行使用
首先是服务的启动关闭命令。
1 | 关闭所有服务 |
hdfs命令是操作HDFS文件系统上的资源,只要打开了HDFS服务,就可使用命令行操作,与当前所在的Linux目录无关。
ls
1 | 格式:hdfs dfs -ls URI |
ls -R
1 | 格式 : hdfs dfs -ls -R URI |
mkdir
1 | 格式 : hdfs dfs [-p] -mkdir <paths> |
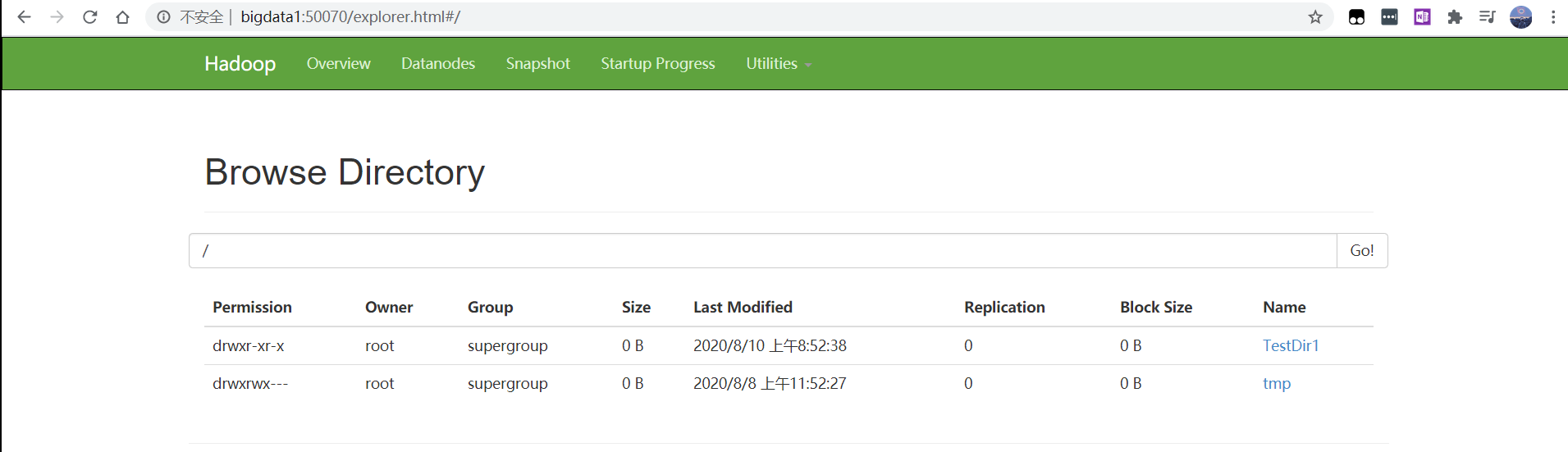
在hdfs文件系统中,可以通过50070端口查看文件系统的结构。
put
1 | 格式 : hdfs dfs -put <localsrc> ... <dst> |
moveFromLocal
1 | 格式 : hdfs dfs -moveFromLocal <localsrc> <dst> |
get
1 | 格式 : hdfs dfs -get [-ignorecrc] [-crc] <src> <localhost> |
mv
1 | 格式 : hdfs dfs -mv URI <dst> |
rm
1 | 格式 : hdfs dfs -rm [-r] [skipTrash] URI [URI...] |

cp
1 | 格式 : hdfs dfs -cp URI [URI ...] <dest> |
cat
1 | hdfs dfs -cat URI [uri...] |
chmod
1 | 格式 : hdfs dfs -chmod [-R] URI[URI...] |
chown
1 | 格式 : hdfs dfs -chmod [-R] URI[URI...] |
appendToFile
1 | 格式 : hdfs dfs -appendToFile <localsrc> ... <dest> |
HDFS的高级使用命令
HDFS文件限额配置
在多人共用HDFS的 环境下,配置设置非常重要。特别是在Hadoop处理大量资料的环境,如果没有配额管理,很容易把所有空间用完造成别人无法存取。HDFS的配额设定是针对目录而不是账号,可以让每个账号仅操作某一个目录,然后对目录设置配置。
HDFS文件的限额配置允许我们以文件个数,或者文件大小来限制我们在某个目录上传的 文件数量或者文件内容总量,以便达到我们类似网盘等限制每个用户允许上传的最大的文件的量。
1 | hdfs dfs -mkdir /user/root/dir |
数量限额
1 | hdfs dfsadmin -setQuota 2 dir # 设置该文件下最多只能上传两个文件 |
注意:设置为2,但只能上传 1 个文件,设置为 n,上传 n - 1
1 | hdfs dfsadmin -clrQuota dir # 清除文件数量限额 |
空间大小限额
在设置空间配额时,设置的 空间至少是Block_size * 3(128 * 3 = 384M)大小
1 | hdfs dfsadmin -setSpaceQuota 4k /user/root/dir # 限制空间大小4KB,报错,至少384M |
分析:129M需要被分为两个Block(128M 和 1M),空间限额至少为 2 * 3 * Block_size = 768M。
HDFS的安全模式
安全模式是Hadoop的一种保护机制,用于保证集群中的数据块的安全性。当集群启动时,会首先进入安全模式。当系统出于安全模式时会检查数据块的完整性。
假设我们设置的副本数(即参数dfs.replication)是 3,那么在DataNode上就应该有 3 个副本,若只存在 2 个副本,那么比例就是 2 / 3 , HDFS默认的副本率为0.999,小于副本率,系统会自动的复制副本到其他DataNode。若系统超过我们设定的副本数,那么系统也会删除多余的副本。
在安全模式下,文件系统只接受读数据请求,而不接受删除、修改等变更请求。当整个系统达到安全标准时,HDFS会自动离开安全模式。
安全模式操作命令
1 | hdfs dfsadmin -safemode get # 查看安全模式状态 |
HDFS基准测试
实际生产环境中,Hadoop环境搭建完成后,第一件事情就是进行压力测试,测试我们的集群的读取和写入速度,测试我们的网络带宽是否满足一些测试基准
测试写入速度
向HDFS文件系统中写入数据,10文件,每个文件 10M ,文件存放的地点:/benchmarks/TestDFSIO中。
1 | cd /export/servers/ # 测试会生成结果文件,放到该目录下 |
命令执行完,该目录下生成测试结果的文件TestDFSIO_results.log,可以通过vi命令查看。
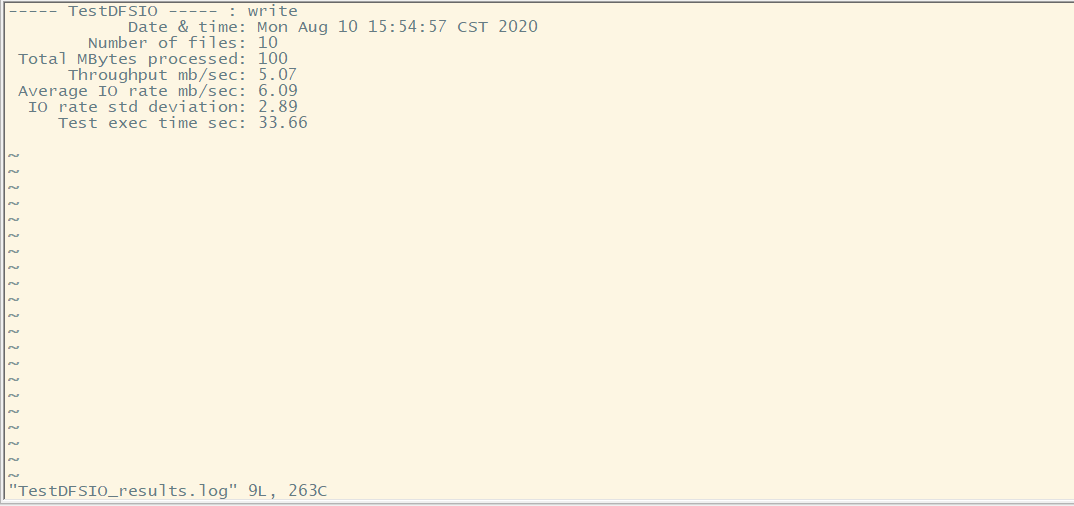
也可通过命令查看写入速度结果
1 | hdfs dfs -text /benchmarks/TestDFSIO/io_write/part-00000 |
测试读取速度
1 | hadoop jar /export/servers/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.7.jar TestDFSIO -read -nrFiles 10 -fileSize 10MB |
只需把 write 改为 read即可,其他文件查看等与上步一致。
清除测试数据
1 | hadoop jar /export/servers/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.7.jar TestDFSIO clean |
注意:清除的是测试文件,但benchmarks还在,里面的数据清空;同样,TestDFSIO_results.log 也在。
HDFS的写入和读取过程
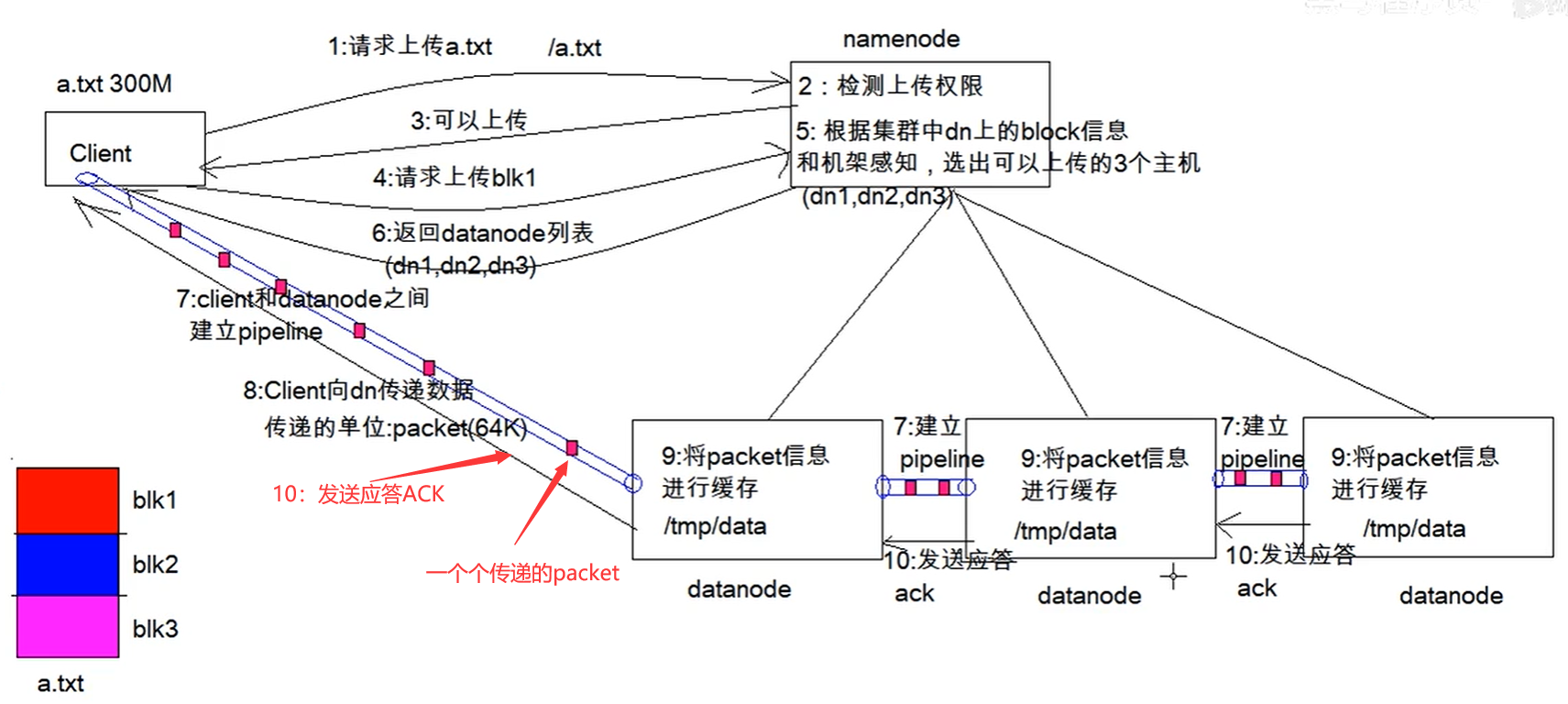
写入过程
读取过程
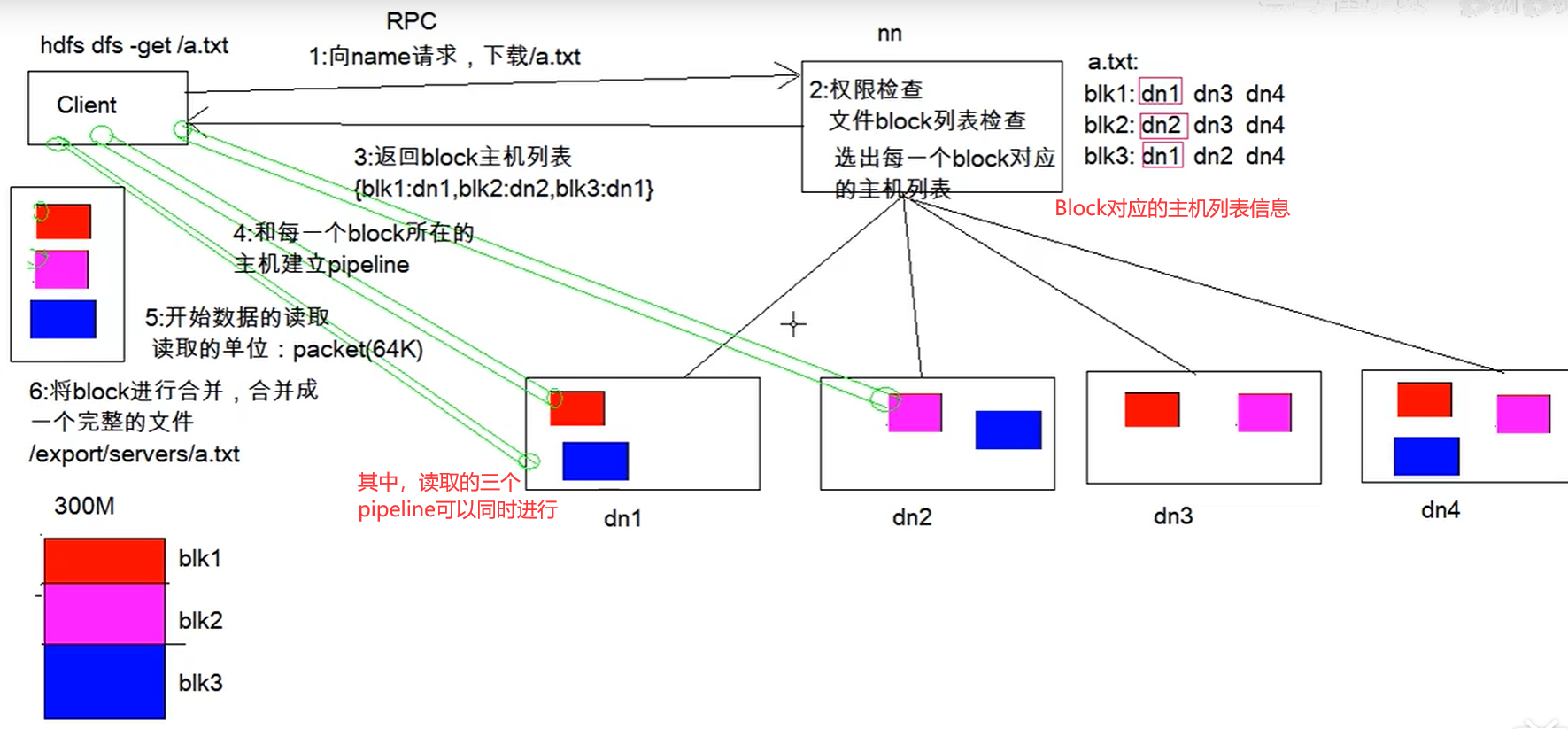
HDFS的元数据辅助管理
当Hadoop的集群中,NameNode的所有元数据信息都保存在了FsImage 与 Edits 文件当中。元数据信息的 保存目录配置在了hdfs-site.xml当中。
FsImage 和 Edits 详解
edits
- edits 存放了客户端最近一段时间的操作日志
- 客户端对HDFS进行写文件时会首先被记录在edits文件中
- edits修改时元数据也会更新
fsimage
- NameNode中关于元数据的镜像,一般称为检查点,fsimage存放了一份比较完整的元数据信息
- 因为fsimage是NameNode的完整镜像,如果每次都加载进就非常损耗内存和CPU,所以一般开始时对NameNode的操作都放在edits中
- 随着edits内容增大,就需要在一定时间点和fsimage合并
fsimage中的文件信息查看
使用命令 hdfs oiv
1 | cd /export/servers/hadoop-2.7.7/hadoopDatas/namenodeDatas/current |
edits文件信息查看
1 | cd /export/servers/hadoop-2.7.7/hadoopDatas/nn/edits/current/ |
SecondaryNameNode如何辅助管理fsimage和 edits文件?
只有在NameNode重启时,edit logs才会合并到fsimage文件中,从而得到一个文件系统的最新快照。但是在产品集群中NameNode是很少重启的,这也意味着当NameNode运行了很长时间后,edit logs文件会变得很大。在这种情况下就会出现下面一些问题:
- edit logs文件会变的很大,怎么去管理这个文件是一个挑战。
- NameNode的重启会花费很长时间,因为有很多改动[笔者注:在edit logs中]要合并到fsimage文件上。
- 如果NameNode挂掉了,那我们就丢失了很多改动因为此时的fsimage文件非常旧。[笔者注: 笔者认为在这个情况下丢失的改动不会很多, 因为丢失的改动应该是还在内存中但是没有写到edit logs的这部分。]
现在我们明白了NameNode的功能和所面临的挑战 - 保持文件系统最新的元数据。那么,这些跟Secondary NameNode又有什么关系呢?
SecondaryNameNode就是来帮助解决上述问题的。SecondaryNameNode定期合并fsimage 和 edits,把 edits 控制在一个范围内。
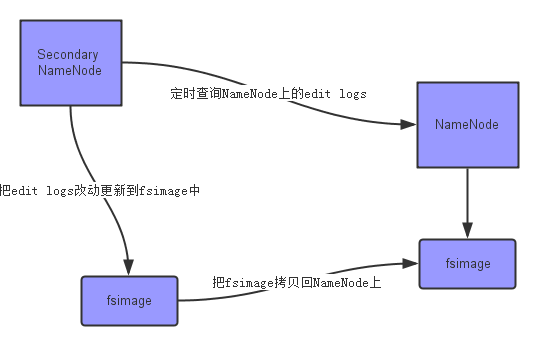
上面的图片展示了Secondary NameNode是怎么工作的。
- 首先,它定时到NameNode去获取edit logs,并更新到fsimage上。[笔者注:Secondary NameNode自己的fsimage]
- 一旦它有了新的fsimage文件,它将其拷贝回NameNode中。
- NameNode在下次重启时会使用这个新的fsimage文件,从而减少重启的时间。
Secondary NameNode的整个目的是在HDFS中提供一个检查点。它只是NameNode的一个助手节点。这也是它在社区内被认为是检查点节点的原因。
现在,我们明白了Secondary NameNode所做的不过是在文件系统中设置一个检查点来帮助NameNode更好的工作。它不是要取代掉NameNode也不是NameNode的备份。所以从现在起,让我们养成一个习惯,称呼它为检查点节点吧。
