本篇为大数据的Hadoop技术入门,主要是环境的安装和Hadoop的编译。
Hadoop介绍
狭义上,Hadoop就是指Hadoop这个软件,它包括:
- HDFS:分布式文件系统
- MapReduce:分布式计算系统
- Yarn:集群资源管理系统
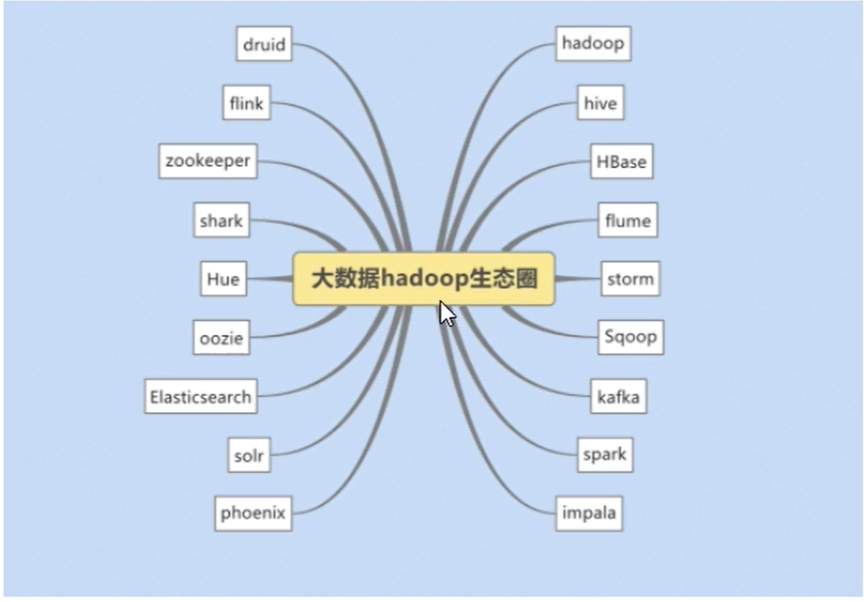
广义上,Hadoop指代大数据的一个生态圈,包括很多其他软件。
Hadoop的安装
集群规划
| 服务器IP | 主机名 | NameNode | SecondaryNameNode | dataNode | ResourceManager | NodeManger |
|---|---|---|---|---|---|---|
| 192.168.2.128 | bigdata1 | 是 | 是 | 是 | 是 | 是 |
| 192.168.2.129 | bigdata2 | 否 | 否 | 是 | 否 | 是 |
| 192.168.2.130 | bigdata3 | 否 | 否 | 是 | 否 | 是 |
说明:
NameNode :是HDFS的主节点。
SecondaryNameNode:对 NameNode 做一个辅助管理。
dataNode:从结点。
ResourceManager:分布式计算MapReduce的主节点。
NodeManger:分布式计算MapReduce的从结点。
编译配置过程
主要是根据 B站视频 和 一篇博客 完成的。过程较为麻烦,但自己尝试几乎没有踩坑,需要细心细致的编译源码,并进行后面的配置文件的仔细修改。
这里使用的各个软件的版本号,主机名,目录名等都与教程有些出入,需要自己做出合适修改。
Hadoop集群的启动
只需在bigdata1上启动即可。
1 | cd /export/servers/hadoop-2.7.7 |
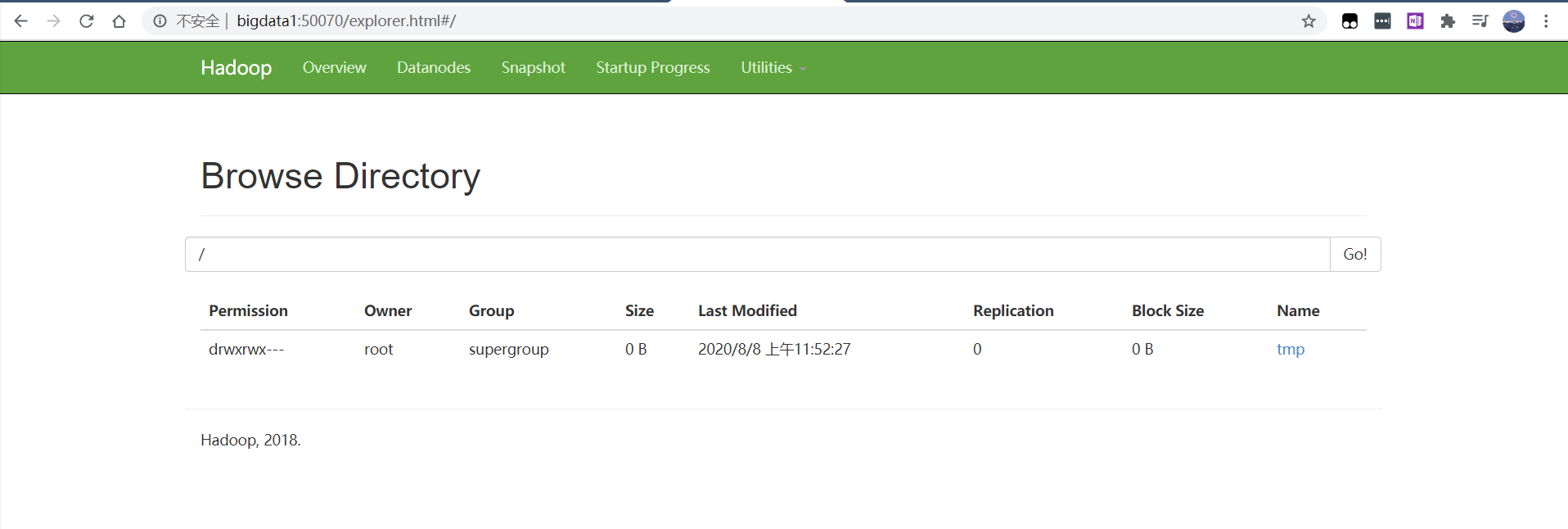
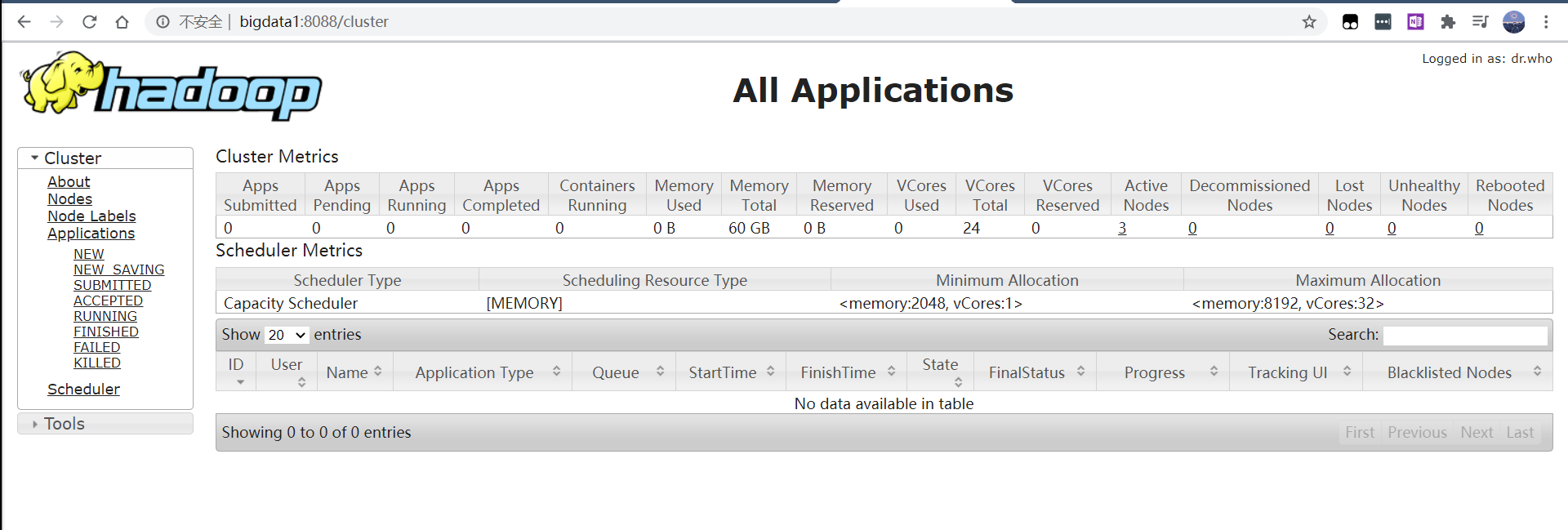
可以通过查看界面完成是否配置成功。
1 | http://bigdata1:50070/explorer.html#/ |
成功页面:
进程列表: