ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。重点内容记录如下。
Zookeeper的介绍和安装
Zookeeper概述
Zookeeper是一个开源的分布式协调服务框架,主要用来解决分布式集群中应用系统的一致性问题和数据管理问题。
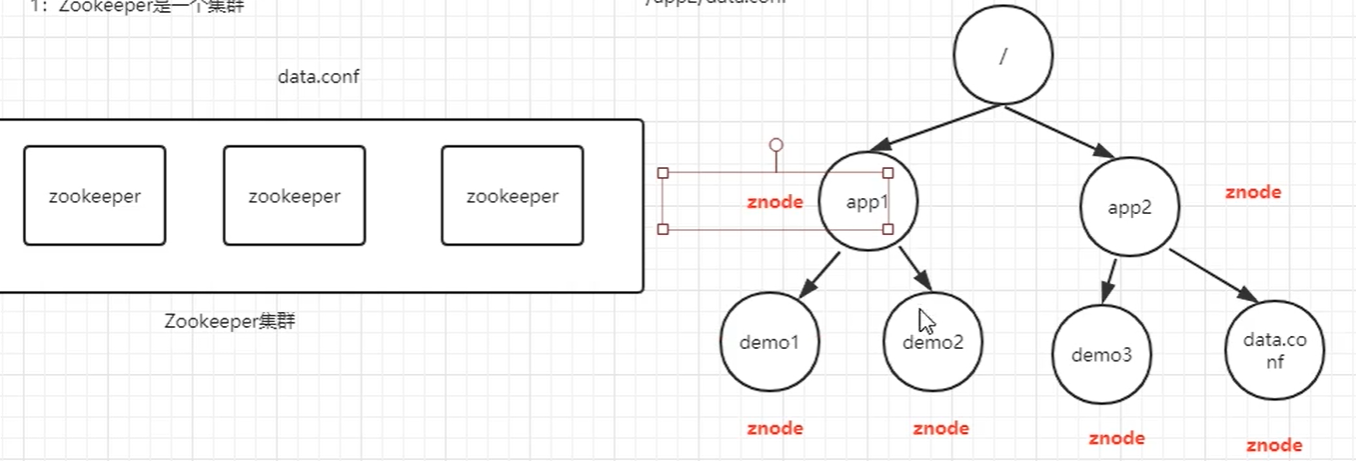
zookeeper是一个集群,可以分布在多台主机上,每台主机都可以看做成一个小型的文件系统,则这个整体就可看作一个分布式文件系统。
关于存储,zookeeper将这个整体看成一个树形结构,每一个结点都是一个Znode。
- Znode是有路径的,例如:/app2/data.conf,这个路径可以理解为是Znode的Name
- Znode可以携带数据,即 既可表示文件目录,也可表示文件。
正因为Znode的特性,所以Zookeeper可以对外提供一个类似于文件系统的试图,可以通过操作文件系统的方式操作Zookeeper
Zookeeper的架构
zookeeper集群是一个基于主从架构的高可用集群,可以24小时不间断工作。
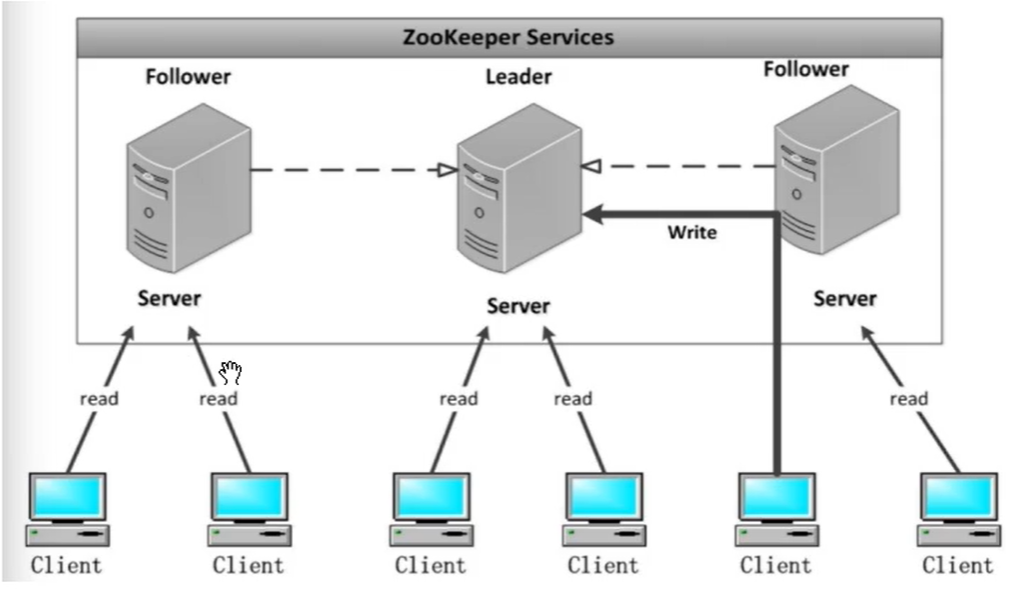
其中,客户机发出读取数据的非事务请求 和 写数据的事务性请求,写操作一般由从主机转发给主主机
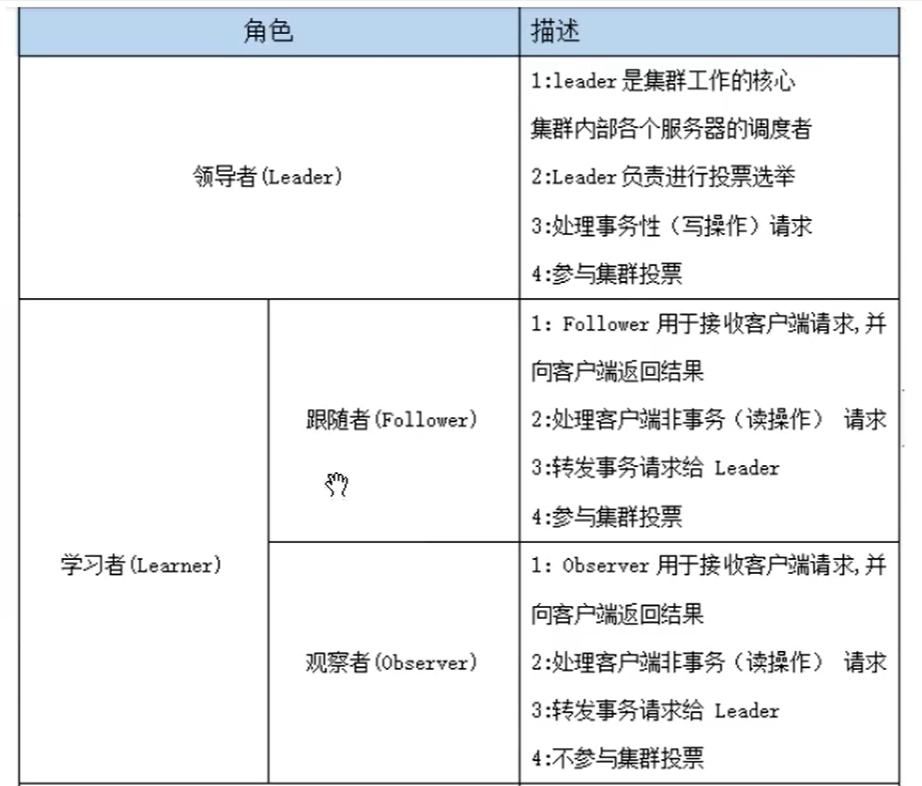
每个服务器承担如下三种角色中的一种
- Leader:一个zookeeper集群同一时间只会有一个实际工作的Leader,它会发起并维护各Follower及Observer的心跳。所有的写操作必须要通过Leader完成再由Leader将写操作广播给其他服务器。
- Follower:一个zookeeper集群可能有多个Followers,它会影响Leader的心跳。Follower可直接处理并返回客户端的读请求,同时将请求转发给Leader处理,并且负责在Leader处理写请求时对请求进行投票。
- Observer:Observer和Follower类似,但无投票权。
Zookeeper的安装和开启
下载zookeeper的压缩包,网址:http://archive.apache.org/dist/
找到zookeeper软件包,下载的是3.4.9版本,下载好.tar.gz压缩包后,传到虚拟机上然后解压到自己定义的安装目录。
1 | cd /export/softwares |
解压好后,修改配置文件。
1 | cd /export/servers/zookeeper-3.4.9/conf/ |
然后对复制的 zoo.cfg 配置文件进行配置。
vi zoo.cfg,修改内容:
1 | dataDir=/export/servers/zookeeper-3.4.9/zkdatas/ # 上面创建的zkdatas目录 |
接下来添加myid配置
在第一台虚拟机上,在上面创建的zkdatas文件夹下创建myid文件,内容为 1 。
然后,把配置好的安装包分发给另外两台虚拟机,并且修改它们的myid,分别设置为 2 和 3 。
1 | scp -r /export/servers/zookeeper-3.4.9/ bigdata2:/export/servers |
启动zookeeper访问
进入到bin目录,使用命令 ./zkServer.sh start启动服务。(启动时需要注意,命令使用规范)
然后验证是否启动成功可以使用命令 jps。

出现 QuorumPeerMain 表示启动成功。若未启动成功,可能的原因就是上面的zoo.cfg未配置正确。
然后我们可以用命令 ./zkServer.sh status 查看状态(注意:一定要启动主节点,即bigdata2,可以提前把三个结点的zookeeper都启动)。可以发现,虚拟机2为 Leader,1 和 3 为 Follower。
至此,一个zookeeper集群搭建完成。
Zookeeper内部结构
Zookeeper的数据模型
zookeeper的数据模型,在结构上和标准文件系统非常相似,都是采用树形层次结构。
zookeeper树中的每个结点被称为一个Znode。
不同之处:
- Znode兼具文件和目录两种特点。
- Znode存数据大小有限制,以KB为单位,主要存储状态信息、配置信息。
- Znode通过路径引用。路径必须是绝对的,因此他们必须由斜杠字符来开头(根节点为 / )。其中 “ /zookeeper ”为系统默认创建的Znode,用以保存管理信息。
- 每个Znode由3部分组成:
- stat:此为状态信息,描述该Znode的版本,权限等信息。
- data:与该Znode关联的数据
- children:该Znode下的子节点
Znode的结点类型
1、Znode结点有两种,分别为 临时节点 和 永久结点 。结点的类型在创建时即被确定,并且不能改变。
- 临时结点:该节点的生命周期依赖于创建它们的会话。会话结束就会被自动删除。临时结点不允许拥有子节点。。
- 永久节点:该节点的生命周期不依赖于会话。
2、Znode还有序列化的特性,如果创建的时候指定的话,该Znode的名字后面会自动追加一个不断增加的序列号。它的格式为 “ %10d ”(10位数字,没有数值的数位用 0 补充,例如“0000000001”)
3、这样便会存在四种类型的Znode结点,分别对应:
- PERSISTENT:永久结点
- EPHEMERAL:临时结点
- PERSISTENT_SEQUENTIAL:永久结点、序列化
- EPHEMERAL_SEQUENTIAL:临时结点、序列化
Zookeeper的Shell客户端操作
1、登录Zookeeper客户端
1 | ./zkCli.sh -server 主机名:2181 |
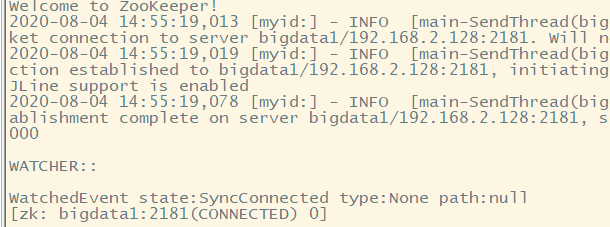
表示登录成功。
退出命令 quit。登录时,省略-server及之后的命令,代表登录本主机的客户端。
2、Zookeeper的常用命令
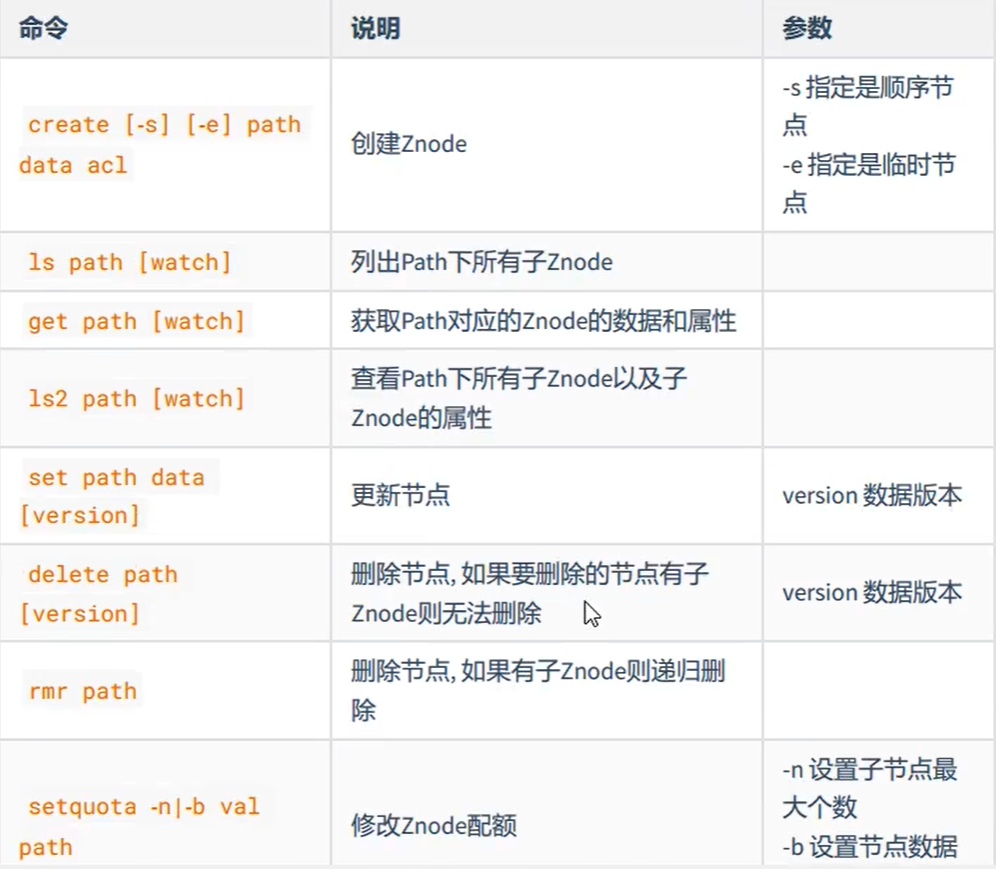
注意:create命令:如果不加参数,创建永久性结点;如果加参数 - s,创建永久性序列化结点;如果只用 - e,创建临时结点;都加上代表临时性序列化结点。
操作实例:
1 | 列出Path下的所有Znode |
3、Znode结点属性
每个Znode都包含了一系列的属性,通过命令get,可以获得结点的属性。
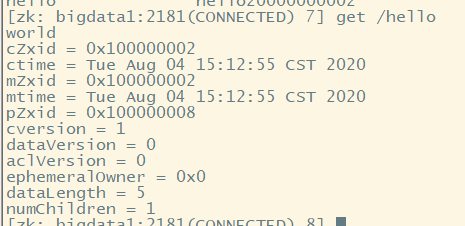
首先第一行是该节点携带的信息。
dataVersion:数据版本号。每次对结点进行set操作,该值都会增1。
cversion:子节点的版本号。当Znode的子节点有变化时,cversion的值就会增1。
aclVersion:ACL的版本号。
cZxid:Znode创建事务的ID。
mZxid:Znode被修改的事务ID,即每次对Znode的修改都会更新mZxid。
ctime:结点创建时的时间戳。
mtime:最近一次更新的时间。
ephemeralOwner:如果该节点为临时结点,该值表示与该节点绑定的session id,如果不是,值为 0。
Zookeeper的watch机制
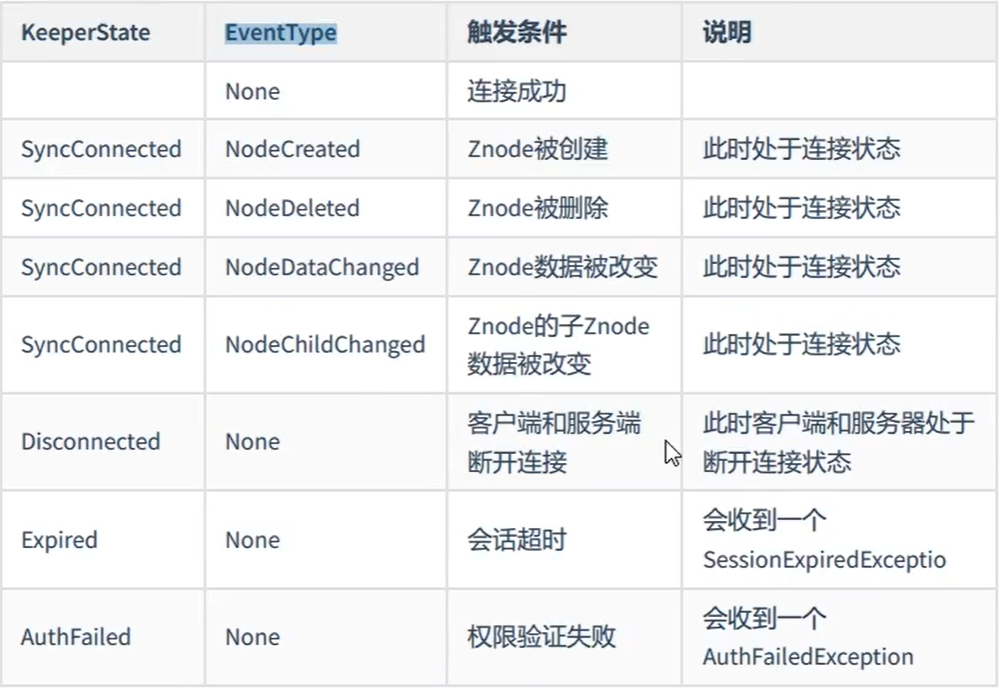
类似于数据库中的触发器,对某个Znode设置 Watcher,当Znode发生变化时,WatchManager会调用对应的Watcher。
当Znode发生删除,修改,创建,子节点的修改时,对应的Watcher会得到通知。
Watcher的特点
- 一次性触发:一个Watcher只会被触发一次,如果需要继续监听,则需要再次添加Watcher。
- 事件封装:Watcher得到的事件是被封装过的,包括三个内容
KeeperState,eventType,path
主要作用:
1、发布和订阅
2、监听集群中主机的存活状态
Zookeeper的JavaAPI操作
这里操作Zookeeper的JavaAPI使用的是一套zookeeper客户端框架Curator,解决了很多Zookeeper客户端非常底层的细节开发工作。
Curator包含了几个包:
- curator-framework:对zookeeper的底层api的一些封装
- curator-recipes:封装了一些高级特性,如:Cache事件监听、选举、分布式锁、分布式计数器等。
Maven依赖(使用curator的版本:2.12.0,对应zookeeper的3.4.x版本,如果不对应,可能有兼容性问题,很可能导致结点操作失败)
实例代码:
1 | package com.thorine.zookeeper_api; |
