本篇总结爬取时 信息标记 和 提取方法 。
信息标记的三种形式
标记后的信息可形成信息组织结构,增加了信息维度
标记的结构与信息一样具有重要价值
标记后的信息可用于通信、存储或展示
标记后的信息更利于程序理解和运用
有三种形式,XML,JSON,YAML
1、XML
1 | <name>...</name> |
2、JSON
1 | "key":"value" |
注意:JSON无法表示注释内容。
3、YAML
缩进表达所属关系。
1 | key : value |
信息提取的一般方法
1、完整解析信息的标记形式
需要标记解析器,例如:bs4库的标签树遍历
- 优点:信息解析准确
- 缺点:提取过程繁琐,速度慢
2、无视标记形式,直接搜索关键信息
对信息的文本查找函数即可。
- 优点:提取过程简洁,速度较快
- 缺点:提取结果准确性与信息内容相关
3、融合方法
结合形式解析与搜索方法,提取关键信息。
需要标记解析器及文本查找函数。
主要学习下面的bs4中的find_all()的查找方法。
基于bs4库的HTML内容查找方法
find_all()
掌握最主要的find_all()方法的使用。
1 | <Tag>.find_all(name, attrs, recursive, string, **kwargs) |
该函数的使用说明:
返回的是列表类型,存储查找的结果
参数解释:
name: 对标签名称的检索字符串
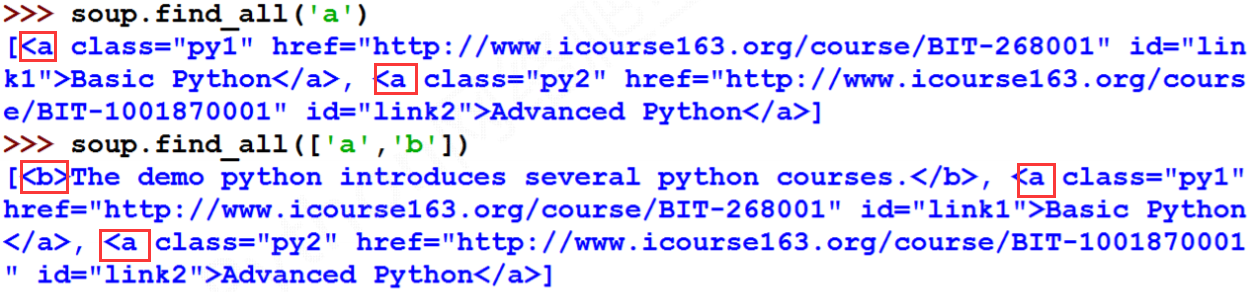

这里引用了正则表达式的相关知识,首先
import re,引入该模块,调用的方法是re.compile('b'),这表示:模糊查询带有’b’的字符串,例如本题,查找带有字符’b’的所有标签,得到结果为 和attrs:对标签属性值的检索字符串,可标注属性检索


1
soup.find('h1', attrs = ['class':'ph']) # 查找h1标签,且属性值class为ph
可见,BeautifulSoup库中的查询是严格的,可以引用re模块来进行模糊查询。
recursive:是否对子孙全部检索,默认True
string:
<>...</>中字符串区域的检索字符串
查找方法的等价形式(更简便)

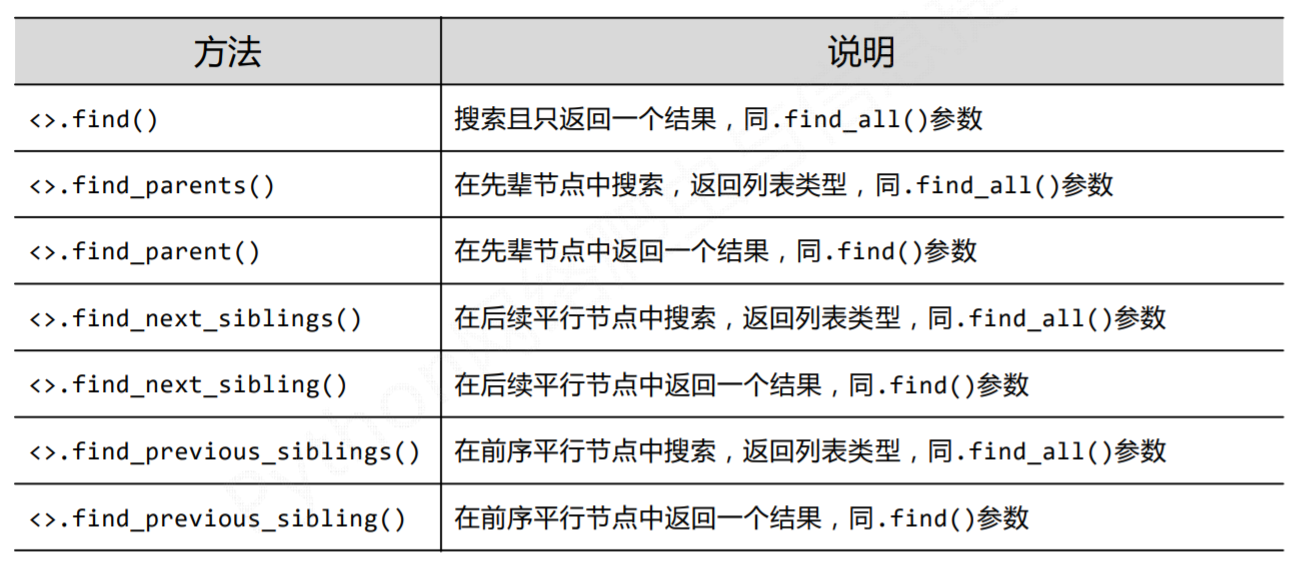
其他查找方法
实例:中国大学的排名爬虫
1 | # CrawUnivRankingA.py |
