>>> soup.p <p class="title"><b>The demo python introduces several python courses.</b></p>
>>> soup.p.string 'The demo python introduces several python courses.'
5、Tag的Comment
提取注释部分。
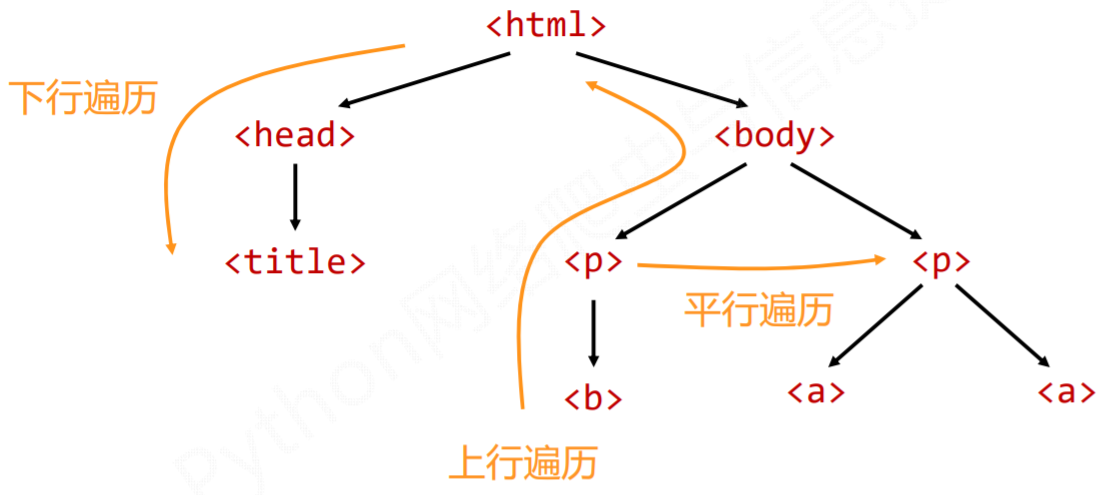
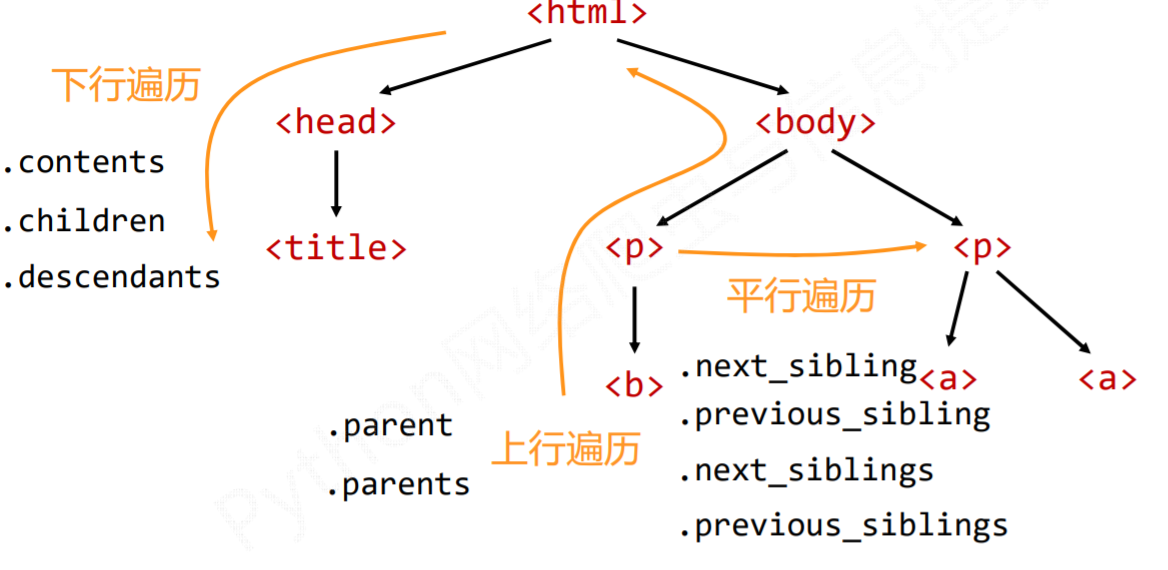
基于bs4库的HTML内容遍历方法
有三种遍历方法:下行、上行和平行遍历。
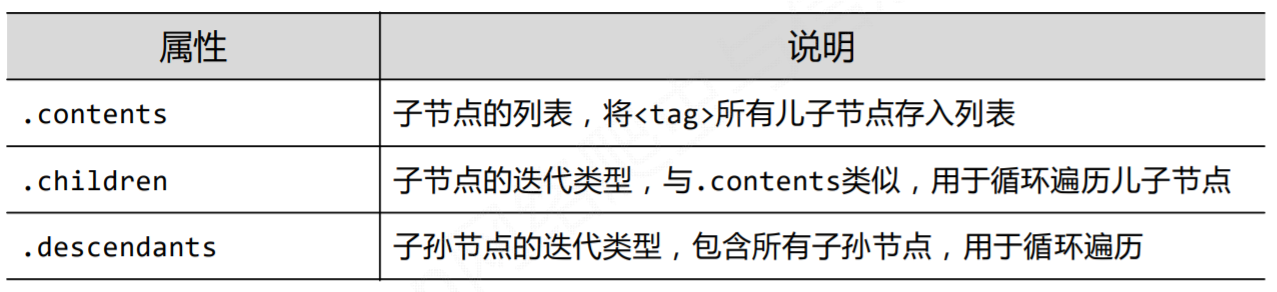
1、标签树的下行遍历
BeautifulSoup类型是标签树的根节点。
1 2 3 4 5
>>> soup.body.contents ['\n', <p class="title"><b>The demo python introduces several python courses.</b></p>, '\n', <p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>, '\n'] >>> len(soup.body.contents) 5
注意:返回的是列表。
遍历方法
1 2 3 4 5 6 7
# 遍历儿子结点 for child in soup.body.children: print(child)
# 遍历子孙结点 for child in soup.body.descendants: print(child)
2、标签树的上行遍历
实例:遍历所有先辈节点,包括soup本身,所以要区别判断
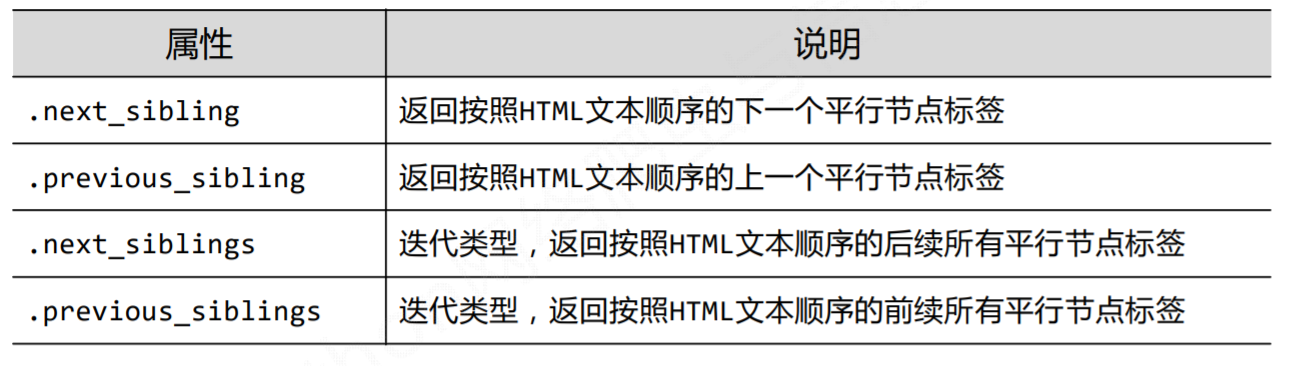
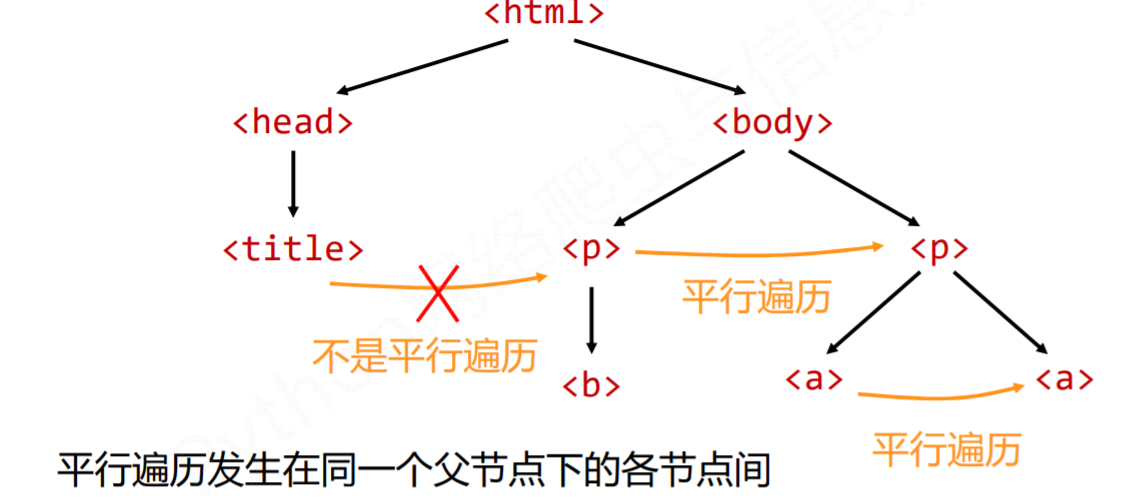
3、标签树的平行遍历
注意:
遍历
1 2 3 4 5
for sibling in soup.a.next_sibling: print(sibling) # 遍历后续结点
for sibling in soup.a.previous_sibling: print(sibling) # 遍历前续结点