这部分是python记录爬虫功能的笔记,刚刚入门,这篇总结 requests 库的使用。
关于更多requests库的知识,可以查看官方网站。
request 库需要安装,比较容易,不再赘述。
requests库中有七个常用方法。
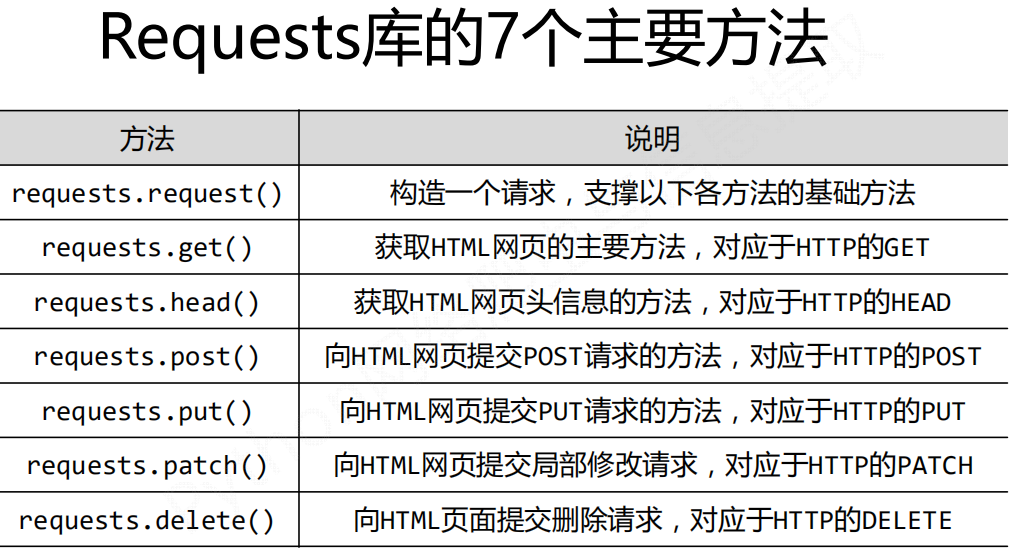
get()方法
获取一个网页最简单的方法就是
1 | r = requests.get(url) |
该方法用于构造一个向服务器请求资源的Request对象,该对象为requests库内部生成的。该方法返回的内容是一个包含服务器资源的Response对象,用r表示,代表一个Response对象。
get方法的完整使用如下:
1 | requests.get(url [, params = None, **kwargs]) |
参数含义:
- url:拟获取页面的url链接
- params:url中的额外参数,字典或字节流格式,可选
- **kwargs:12个控制访问的参数
通过查看requests库的源码我们可以发现,七个方法中,其他六个方法都是对get的调用,所以也可认为只有一个get()方法。
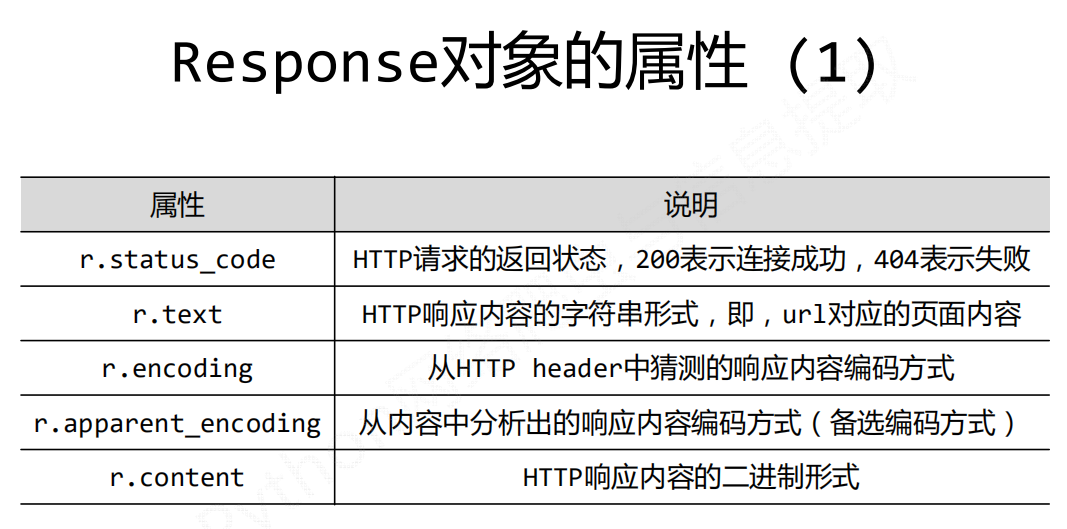
Response对象
Response对象包含爬虫返回的所有内容。
Response对象的属性
理解Requests库的异常
爬取网页的通用代码框架
网络连接有风险,异常处理很重要。
Request对象的异常
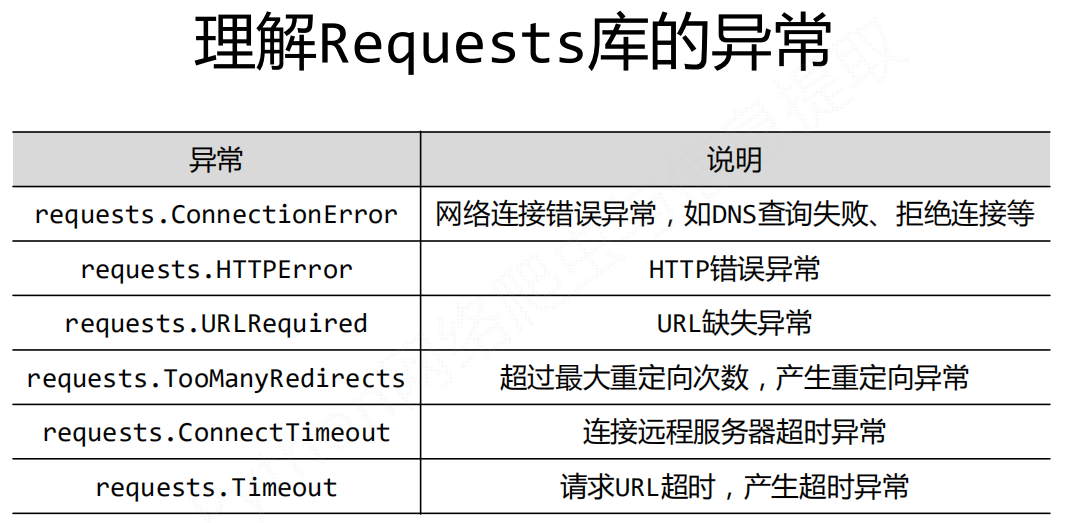
Response对象的异常

爬取页面的通用代码框架
1 | import requests |
HTTP协议及requests库方法
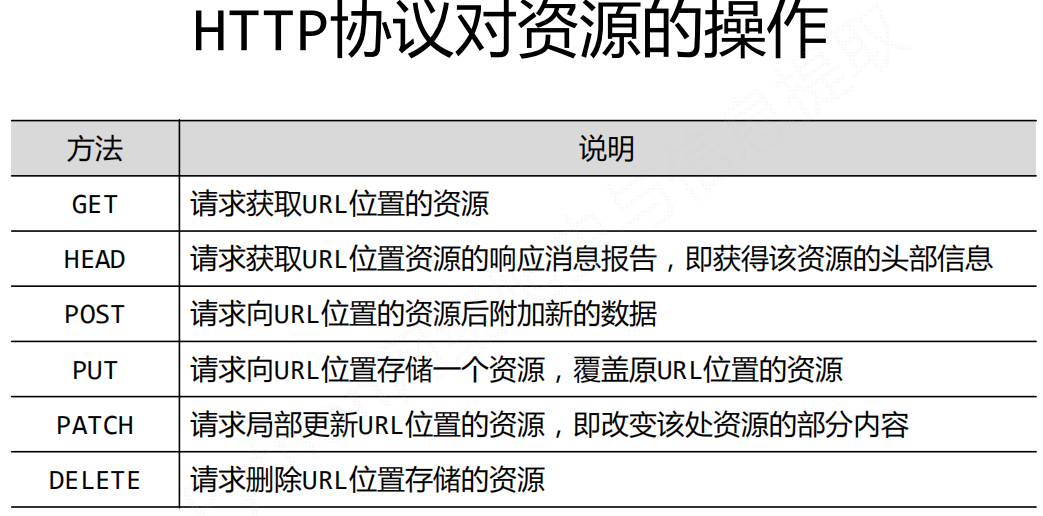


一些方法的简单举例


Requests库的主要方法解析
1. requests.request(method, url, \kwargs)
- method:请求方式,对应get/put/post等7种
- url:拟获取页面的url链接
- **kwargs:控制访问的参数,共13个
method的7种
1 | r = requests.request('GET', url, **kwargs) |
kwargs**: 控制访问的参数,均为可选项
params : 字典或字节序列,作为参数增加到url中

data : 字典、字节序列或文件对象,作为Request的内容

json : JSON格式的数据,作为Request的内容

headers : 字典,HTTP定制头

files : 字典类型,传输文件

timeout : 设定超时时间,秒为单位

proxies : 字典类型,设定访问代理服务器,可以增加登录认证

cookies : 字典或CookieJar,Request中的cookie
auth : 元组,支持HTTP认证功能
allow_redirects:True/False,默认为True,重定向开关
stream:True/False,默认为True,获取内容立即下载开关
verify:True/False,默认为True,认证SSL证书开关
cert:本地SSL证书路径
2. requests.get(url, params=None, \kwargs)
∙ url : 拟获取页面的url链接
∙ params : url中的额外参数,字典或字节流格式,可选
∙ **kwargs: 12个控制访问的参数
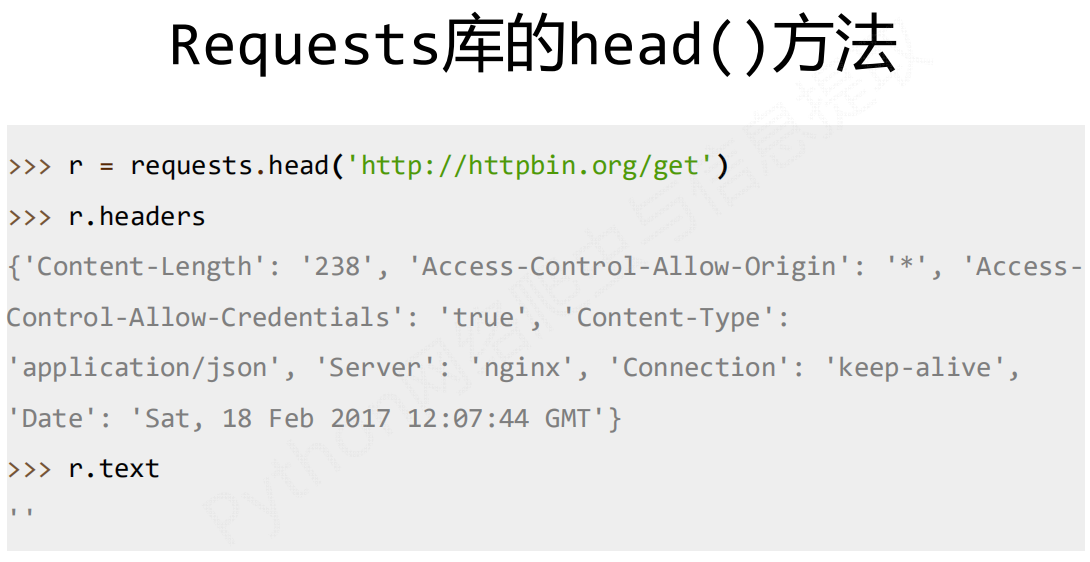
3. requests.head(url, \kwargs)
∙ url : 拟获取页面的url链接
∙ **kwargs: 12个控制访问的参数
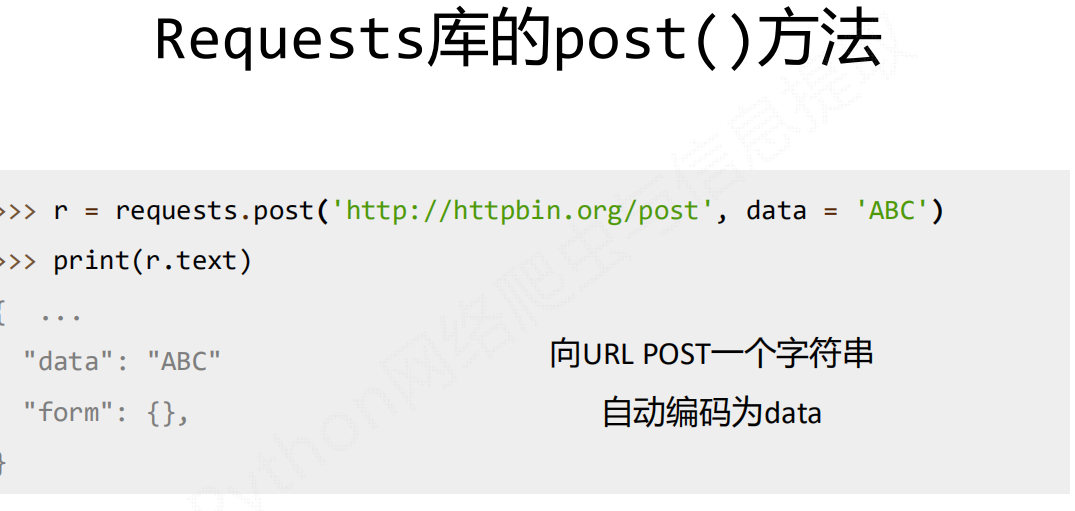
4. requests.post(url, data=None, json=None, \kwargs)
∙ url : 拟更新页面的url链接
∙ data : 字典、字节序列或文件,Request的内容
∙ json : JSON格式的数据,Request的内容
∙ **kwargs: 12个控制访问的参数
5. requests.put(url, data=None, \kwargs)
∙ url : 拟更新页面的url链接
∙ data : 字典、字节序列或文件,Request的内容
∙ **kwargs: 12个控制访问的参数
6. requests.patch(url, data=None, \kwargs)
∙ url : 拟更新页面的url链接
∙ data : 字典、字节序列或文件,Request的内容
∙ **kwargs: 12个控制访问的参数
7. requests.delete(url, \kwargs)
∙ url : 拟删除页面的url链接
∙ **kwargs: 12个控制访问的参数
其他注意事项
HTTP请求头常见参数
User-Agent:浏览器名称,如果我们使用爬虫发送请求,那么我们的User-Agent就是Python,很容易被反爬虫检测到;Referer:表明当前请求是从哪个URL过来的,这个一般也可以用来做反爬虫技术。如果不是从指定页面过来的,那么就不做相关的响应。Cookie:http协议视无状态的,也就是从一个人发送了两次请求,服务器没有能力知道这两个请求是否来自同一个人。因此这时候就用cookie来做标识。一般如果想要做登录后才能访问的网站,那么就需要发送cookie信息了。
常见响应状态码
200:请求正常,服务器正常返回数据;301:永久重定向,比如在访问www.jingdong.com的时候回重定向到www.jd.com;302:临时重定向,比如在访问一个需要登录的页面的时候,而此时没有登录,那么就会重定向到登录界面;400:请求的url在服务器上找不到,换句话说就是请求url错误;403:服务器拒绝访问,权限不够;500:服务器内部错误,可能是服务器出现bug了。
Cookies和Session
cookies
1 | import requests |
Session
1 | import requests |
