基于上次的函数基本知识,本篇总结python中文件的相关操作。
文件的基本操作
- 打开文件
- 读写等操作
- 关闭文件
打开
在python中,使用open函数,可以打开一个已经存在的文件,或者创建一个新文件,语法如下:
1 | open(name, mode, encoding='utf-8') |
- name:是要打开的目标文件名的字符串(可以包含具体路径)
- mode:设置打开文件的模式(访问模式):只读、只写、追加等
- encoding:指定编码
打开文件模式
| 模式 | 描述 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
注意:
- 只要带 b 的,都是 以二进制格式打开文件
- 带 + 的,打开文件用于读写
- a ,文件指针在结尾
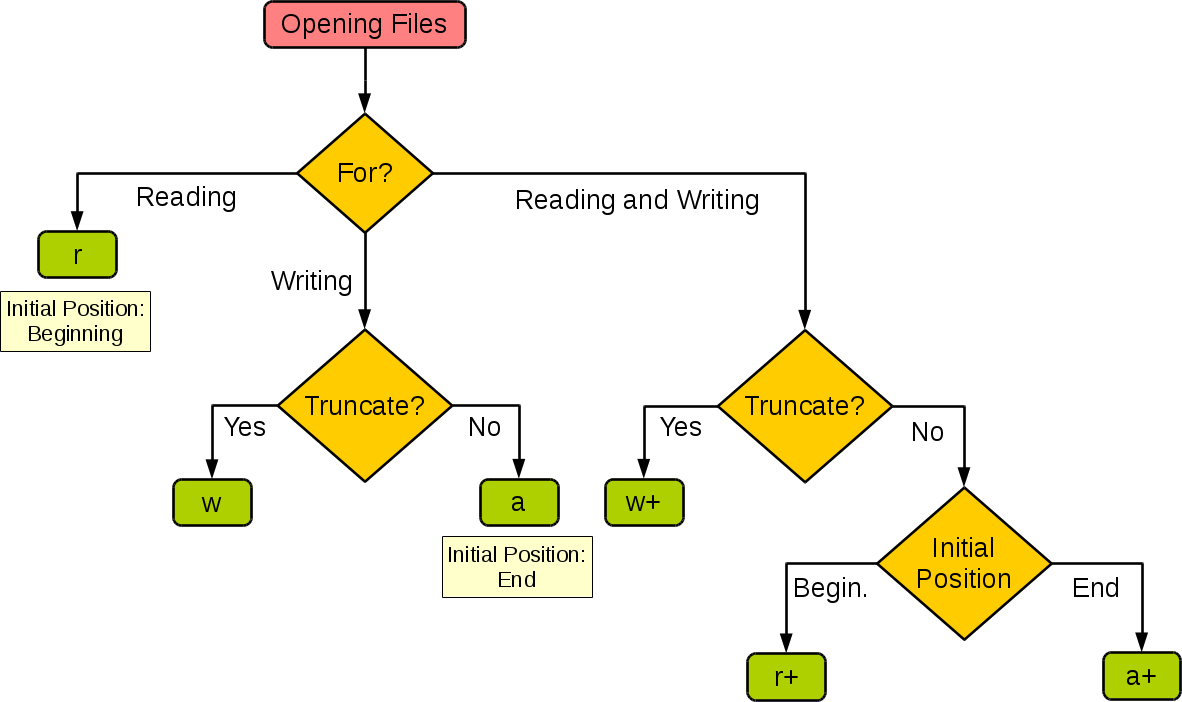
注:
- Truncate:截断
- Initial Position:初始位置
使用
1 | f = open('test.txt', 'w') # f代表文件对象 |
文件对象方法
写
语法
1
文件对象.write('内容')
读
read()
1
文件对象.read(num)
num表示要从文件中读取的数据的长度(单位是字节),可省略
readlines()
readlines可以按照行的方式把整个文件中的内容进行一次性读取,并且返回的是一个列表,其中每行的数据为一个元素
1
2
3f = open('test.txt')
content = f.readlines() # ['aa\n','bb\n','cc']
f.close()readline()
一次读取一行内容
移动文件指针__seek()
语法:
1 | 文件对象.seek(偏移量, 起始位置) |
起始位置:
- 0:文件开头
- 1:当前位置
- 2:文件结尾
1 | f = open('test,txt', 'r+') |
文件备份
需求:用户输入当前目录下任意文件名,程序完成对该文件的备份功能(test[备份].txt)
步骤
- 接收用户输入的文件名
- 规划备份文件名
- 备份文件写入数据
代码实现
接受用户输入目标文件名
1
old_name = input('请输入您要备份的文件名:')
规划备份文件名
- 提取目标文件后缀(字符串最后的一个点才是后缀的点)
- 组织备份的文件名,xx[备份]后缀
1
2
3
4
5
6
7# 以sound.txt.mp3文件名为例
index = old_name.rfind('.') # 提取文件后缀名中“.”的下标 9
# old_name[:index] 源文件名(无后缀) sound.txt
# old_name[index:] 后缀名 .mp3
new_name = old_name[:index] + '[备份]' + old_name[index:]备份文件写入数据
- 打开源文件 和 备份文件
- 将源文件数据写入备份文件
- 关闭文件
1
2
3
4
5
6
7
8
9
10
11old_f = open(old_name, 'rb') # 以二进制的方式读写
new_f = open(new_name, 'wb')
while True:
con = old_f.read(1024)
if len(con) == 0:
break; #表示读完,退出循环
new_f.write(con)
old_f.close()
new_f.close()
文件和文件夹的操作
在python中文件和文件夹的操作要借助os模板里面的相关功能,具体步骤如下:
导入os模块
1
import os
使用os模块相关功能
1
os.函数名()
文件重命名
1 | os.rename(目标文件名, 新文件名) |
删除文件
1 | os.remove(目标文件名) |
创建文件夹
1 | os.mkdir(文件夹名字) |
删除文件夹
1 | os.rmdir(文件夹名字) |
获取当前目录
1 | os.getcwd() |
改变默认目录
1 | os.chdir(目录) |
需求:在A文件夹里创建B文件夹
1 | os.chdir('A') |
获取目录列表
1 | os.listdir(目录) #获取该目录下的所有文件,返回一个列表 |
例子:
1 | print(os.listdir('A')) # B |
读取JSON文件
我们使用Python中的json模块就可以将字典或列表以JSON格式保存到文件中,代码如下所示。
1 | import json |
json模块主要有四个比较重要的函数,分别是:
dump- 将Python对象按照JSON格式序列化到文件中dumps- 将Python对象处理成JSON格式的字符串load- 将文件中的JSON数据反序列化成对象loads- 将字符串的内容反序列化成Python对象
这里出现了两个概念,一个叫序列化,一个叫反序列化。自由的百科全书维基百科上对这两个概念是这样解释的:
- 序列化(serialization)在计算机科学的数据处理中,是指将数据结构或对象状态转换为可以存储或传输的形式,这样在需要的时候能够恢复到原先的状态,而且通过序列化的数据重新获取字节时,可以利用这些字节来产生原始对象的副本(拷贝)。
- 与这个过程相反的动作,即从一系列字节中提取数据结构的操作,就是反序列化(deserialization)”。
